A genealógiai kapcsolathálózatok nem pusztán elméleti szinten lehetnek érdekesek a történészek számára. A hálózatosság különböző megnyilvánulásainak kutatásában, mivel adatokkal való munkáról van szó, a gyakorlati alkalmazás lehetőségei ugyanilyen fontossággal bírnak. A hátterében álló adatbázishoz való hozzáférés, az abból leszűrt adatok hálózattá alakítása, majd a hálózatok elemzése mind-mind speciális ismereteket igényel. Hiszen hiába vannak történészként szuper elgondolásaink, ha technikailag nem tudjuk azokat megvalósítani. A hálózatkutatás egy tipikusan ilyen problémákat felvető terület.
A kérdéses technikák gyakorlati kipróbálásához viszont tesztadatokra van szükség. Jelen esetben olyan genealógiai adatokra, amelyeket demonstrációs célokra fel tudok használni a témába vágó posztok megírásakor, ugyanakkor a bemutatott módszerek elsajátításához a blog olvasói is szabadon letölthetnek és használhatnak. S mindemellett persze az adattár előállítása önmagában véve is érdekes problémákat vet fel.
A történészi gyakorlatban egy jól használható genealógiai adatbázis felépítése meglehetősen lassú és sziszifuszi, több évet igénybe vevő munka, mivel számtalan helyről kell összegereblyézni a szükséges adatokat. Ezt a valóságban nem lehet megspórolni. Léteznek azonban olyan technikák, amelyek segítségével a szöveges dokumentumokból ki tudjuk nyerni a releváns genealógiai információkat. Ebben a blogposztban erre mutatok egy példát. A feldolgozandó dokumentumok forrása a Genealogie české šlechty (A cseh nemesség genealógiája) nevű honlap, ahol egyszerű szöveges (*.TXT) formátumban sorakoznak a genealógiák, köztük számos magyar főnemesi nemzetség leszármazási kapcsolatai. (Mivel ez a weboldal utoljára 2010-ben frissült, így félő, hogy előbb-utóbb megszűnik. Ezért a Wayback Machine internetes archívum oldaláról is belinkelem.) Ezeket a szöveges dokumentumokat fogom automatizáltan átalakítani egy jól strukturált táblázatos formátumra, amely a későbbiekben megfelelő alapot biztosít egy genealógiai kapcsolathálózat felépítéséhez. És sok minden máshoz is.
Figyelem! A bemutatott eljárással létrehozott adathalmaz a blogon megjelenő módszerek tesztelését, gyakorlati kipróbálását szolgálja. Kizárólag ebből a célból állítom elő. A Genealogie české šlechty oldalról származó adatok eredeti forrása nem beazonosítható, ezért alapos ellenőrzés nélkül nem alkalmasak a tudományos igényű feldolgozásra!
Az alábbiakban R nyelven (v4.0.3) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
# A szükséges csomagok betöltése.
# A legelső használat előtt az install.packages("...") utasítással telepíteni
# kell ezeket. A ... helyére az adott csomag neve írandó.
library(stringr)
library(rebus)
library(lubridate)
library(dplyr)
# Ide a saját munkakönyvtárunk elérését kell beírni!
setwd("C:/Munkakönyvtár")A genealógiai adatok azonosítása reguláris kifejezésekkel
Elsőként tekintsünk meg egy részletet a Széchényi nemzetség genealógiájából! (A Genealogie české šlechty honlapon lévő többi szöveges genealógia felépítése pont ugyanilyen.)

Részlet a Széchényi nemzetség genealógiájából
Emberi észjárással természetesen nem okozhat gondot a különböző genealógiai információk és családi kötelékek azonosítása a dokumentumban. A számítógépnek viszont ez önmagában csak egy semmitmondó karakterhalmaz. Meg kell tehát tanítanunk arra, hogy felismerje a vezeték- és keresztneveket, időpontokat, településeket, házastársakat, gyermekeket. Nyilvánvaló azonban, hogy a lehetőségek annyira sokfélék, hogy ezeket előre nem tudjuk maradéktalanul felsorolni. Itt inkább egy olyan általánosabb szabályrendszerre van szükség, amely a karakterek és karakterláncok (szavak) formai jellemzői, az adott soron belüli, illetve egymáshoz képest való elhelyezkedésük és más hasonló szempontok alapján felismeri, hogy az adott szövegrészlet a genealógiában tulajdonképpen minek feleltethető meg. Az e szabályrendszer alapján összeállított mintákat reguláris kifejezéseknek – angolul regular expression, rövidítve regex – nevezik.
Nézzük meg például, hogy a születési, halálozási, házasságkötési időpontok és helyszínek hogyan fordulnak elő a szövegben. Ezekkel kapcsolatban a következő szabályok figyelhetők meg:
A dátumok jelenléte esetleges. Azaz a hiányuk lehetőségével is számolni kell!
A dátumokat néha megelőzi az “AFT” (után), “BEF” (előtt) vagy “EST” (körül) rövidítés és egy szóköz.
Ha a dátum feltüntetésre került, akkor vagy csak az év (négy számjegy) van megadva, vagy a teljes dátum. Utóbbi egy vagy két számjegyből (nap), egy szóközből, három betűből (a hónap angol rövidítése), egy szóközből és végül négy számjegyből (év) áll. Vagyis ha van dátum, akkor az mindenképpen egy számmal kezdődik (év vagy nap), majd utána opcionálisan következik a maradék.
Amennyiben van valamilyen dátum, akkor a helyszín ezután következik. Az utóbbi jelenléte azonban szintén esetleges.
Ahol meg van adva, ott egy szóköz, az “in” szócska, majd egy újabb szóköz vezeti be a települést. Itt számolni kell azzal is, hogy a háborúban elhunytaknál “k.a.,” (talán killed in action) kitétellel jelzik ezt a tényt. Ezt követi a település elnevezése, amely mindenképpen nagybetűvel kezdődik, kisbetűvel végződik, esetleg több szóból áll és kötőjelet vagy pontot is tartalmazhat.
Ha mindezeket a szabályokat egy reguláris kifejezésbe foglaljuk, akkor ez így néz ki: \s(?:((?:EST|BEF|AFT))\s)?([[:digit:]]{1,4}(?:\s[[:alpha:]]{3}\s[[:digit:]]{4})?)(?:\sin\s[k.a.,]*(\b[:upper:](?:[:alpha:]|-|\s|\.)*[:lower:]\b))? Erre csak egyvalamit mondhat az ember: WTF!?
Szerencsére azonban az R-nek van egy remek csomagja, a rebus, amellyel az angol nyelvből ismert szavak és rövidítések segítségével rakhatjuk össze a reguláris kifejezésünket. Jelen esetben így: SPC %R% optional(group( capture(or("EST", "BEF", "AFT")) %R% SPC)) %R% capture(digit(1,4) %R% optional(group(SPC %R% alpha(3) %R% SPC %R% digit(4)))) %R% optional(group(SPC %R% "in" %R% SPC %R% zero_or_more("k.a.,") %R% capture(BOUNDARY %R% UPPER %R% zero_or_more(or(ALPHA, "-", SPC, DOT)) %R% LOWER %R% BOUNDARY))) Ez persze még mindig eléggé homályosnak tűnhet. De több sorba tagolva, mint látni fogjuk, már egészen olvasható. Tapasztalatom szerint a rebus működése rövid idő alatt készségszinten elsajátítható.
A születések esetében a “born”, a halálozások esetében a “died” szó, a házasságkötéseknél pedig a házastárs neve előzi meg a mintaIdopTelep néven elmentett reguláris kifejezésünket. A létrehozott szabályrendszert tehát többféle szituációban is használni tudjuk. Ennek alapján végül a következő három adatot kapjuk meg (az NA itt azt jelenti, hogy a kérdéses adat hiányzik a genealógiából):
A dátum pontossága, konkrétan “EST” / “BEF” / “AFT” / NA
Maga a dátum, például “1681” / “14 Oct 1738” / NA
A település neve, például “Széplak” / NA
Ezzel azonban még mindig nem vagyunk készen, mert a megszerzett dátumokat át kell alakítanunk egy használható formára. Pillanatnyilag ugyanis néhol van valamink, máshol nincs, néha csak az év, máskor a teljes dátum, hol pontosan megadva, hol nem. Ezeket az adatokat egységes módon kell rögzíteni!
Én a dátumokat négy külön mezőben szoktam tárolni: év, hónap, nap, pontosság. Utóbbinál 1 = pontosan, 2 = körül, 3 = előtt, 4 = után. Ez egy saját kódolási konvenció. Ahogy az is, hogy a nem ismert adatokat a 9999-es értékkel helyettesítem. Azaz egy olyan számmal, amely normál körülmények között nem fordulhatna elő. (Nincs ilyen év, hónap, nap…) Én következetesen ezt használom mindenféle adatgyűjtés során. Egyrészt ebből tudom, hogy az adott cella nem véletlenül maradt üres. Másrészt pedig az üresen hagyott cellák hibát okozhatnak akkor, ha különböző táblázatokból származó adatokat akarunk összefésülni. Ez egy hosszú évek óta alkalmazott és jól bevált eljárás nálam. (Később a válások kapcsán előkerül a kódban a 8888-as érték is. Ez a “nem vonatkozik rá” jelentéssel bír. A válásra csak elvétve szerepel információ a genealógiában. De ennek hiánya nem azt jelenti, hogy ismeretlen lenne a számunkra. Akinél ez nincsen feltüntetve, arról az illetőről azt feltételezem, hogy nem vált el.)
A szöveges dokumentumokból kinyert adatok tehát utófeldolgozásra szorulnak. A feldolgIdopTelep nevű eljárás funkciója az, hogy a bemenetként megkapott adatokat a felvázolt egységes formátumra konvertálja.
A születési, halálozási és házassági adatok azonosítása mellett természetesen az érintett személyek nevét is szeretnénk kinyerni a dokumentumból. Az adott nemzetség nevét – mai fogalmainkkal élve a vezetéknevet – azonosító mintaNemzNev reguláris kifejezés azon alapul, hogy ez az információ csupa nagybetűvel van írva a szövegben, ezen kívül legfeljebb kötőjel fordulhat elő benne. (A nemzetség nemesi előneve nem érdekes a számomra, azt nem gyűjtöm be.) A keresztneveket azonosító mintaKerNev reguláris kifejezés alapvetően a nagybetűvel kezdődő és kisbetűvel folytatódó szavakat keresi. De ez persze nem ilyen egyszerű. Sokaknak ugyanis több keresztneve is volt, bizonyos keresztnevek zárójelben vannak a szövegben, mások kötőjelel vagy a “de” szócskával vannak elválasztva. Ezekre a szempontokra mind-mind figyelni kell. Első próbálkozásra gyakran nem is sikerülnek tökéletesre a reguláris kifejezések. Menet közben csiszolgatni kell őket.
Fontos még megemlíteni, hogy ezek a minták önmagukban állva olyan szövegrészleteket is azonosíthatnak, amelyek irrelevánsak a számunkra. Ezért a reguláris kifejezéseket általában kontextusba kell helyezni. Utaltam például már rá, hogy a születéseket a “born” szó, a halálozásokat a “died” előzi meg. Vagyis ha ezekre az adatokra van szükségünk, akkor a "born" %R% mintaIdopTelep vagy "died" %R% mintaIdopTelep formában használjuk az adott reguláris kifejezést. De viszonyítási pont lehet például egy bekezdés eleje és vége, vagy egy másik mintával sikeresen megtalált szövegrészlet. Emellett azzal is játszani tudunk, hogy az adott bekezdésben csak az első találat eredményét kérjük vissza, vagy mindet.
# A genealógiai adatokat azonosító reguláris kifejezések.
mintaNemzNev <- BOUNDARY %R% UPPER %R% one_or_more(or(UPPER,"-")) %R% BOUNDARY
mintaKerNev <- one_or_more(group(or(SPC, "-", ",", SPC %R% OPEN_PAREN, SPC %R% "de" %R% SPC) %R% UPPER %R% one_or_more(or(LOWER, CLOSE_PAREN))))
mintaIdopTelep <- SPC %R%
optional(group(capture(or("EST", "BEF", "AFT")) %R% SPC)) %R%
capture(digit(1,4) %R% optional(group(SPC %R% alpha(3) %R% SPC %R% digit(4)))) %R%
optional(group(SPC %R% "in" %R% SPC %R% zero_or_more("k.a.,") %R% capture(BOUNDARY %R% UPPER %R% zero_or_more(or(ALPHA, "-", SPC, DOT)) %R% LOWER %R% BOUNDARY)))
# A dátumok és települések feldolgozására szolgáló eljárás.
feldolgIdopTelep <- function(bemenet) {
datum <- try(parse_date_time2(bemenet[3], "%d %b %Y"))
if (is.na(bemenet[3])) {
ev <- 9999
ho <- 9999
nap <- 9999
pont <- 9999
} else if (!is.na(datum)) {
ev <- year(datum)
ho <- month(datum)
nap <- day(datum)
pont <- NA
} else {
ev <- as.numeric(bemenet[3])
ho <- 9999
nap <- 9999
pont <- NA
}
if (is.na(bemenet[2]) & is.na(pont)) {
pont <- 1
} else if (bemenet[2] %in% "EST") {
pont <- 2
} else if (bemenet[2] %in% "BEF") {
pont <- 3
} else if (bemenet[2] %in% "AFT") {
pont <- 4
}
if (is.na(bemenet[4])) {
hely <- "Ismeretlen"
} else {
hely <- bemenet[4]
}
return(list(ev,ho,nap,pont,hely))
}A genealógia szétbontása konkrét személyekre
Az elmondottak alapján már azonosítani tudjuk a számunkra érdekes genealógiai információkat. További lényeges kérdésként merülhet fel, hogy ezek pontosan kihez tartoznak? Ezt szemrevételezéssel nyilván meg tudjuk állapítani, de a számítógép magától erre sem képes. Közölni kell tehát vele azt is, hogy egy-egy személyhez a szöveges dokumentum melyik sorai kapcsolódnak. Ahogy a fentebbi szemelvényen látható, a genealógiában lévő minden személynek van egy azonosító száma. Vagyis ahol a sor elején egy maximum háromjegyű számot, pontot, majd szóközt találunk (reguláris kifejezéssel: START %R% digit(1,3) %R% DOT %R% SPC), ott biztosak lehetünk benne, hogy egy konkrét személyre vonatkozó bejegyzés kezdősorával van dolgunk. Ez a bejegyzés addig a sorig tart, amelyben egy újabb személy azonosítójával találkozunk, illetve ahol véget ér a dokumentum.
Ezzel a logikával meg tudjuk határozni, hogy egy konkrét illetőhöz a dokumentum melyik sorai tartoznak. A feldolgozás alapegysége ezen sorok összessége lesz, amit itt bejegyzésnek hívok. Ezeken fogunk majd egyenként végigmenni.
Az adatokat két táblázatban gyűjtöm. Az egyenek nevű tábla minden sora egy-egy személynek felel meg. Mégpedig úgy, hogy a szöveges genealógiából kinyert személyi azonosító szám adja meg a táblázat megfelelő sorát. Például az 53-as azonosítójú Széchényi Pál adatait a táblázat 53. sorában rögzítjük. Ez így praktikus. Elvileg tehát a táblázatunknak kezdetben pontosan annyi sora van, mint amekkora a genealógia utolsó szereplőjének azonosítója. (A 330 Széchényihez 330 sor tartozik.) A gyakorlatban viszont rá kellett jönnöm, hogy ez sajnos nem mindig van így. Az Erdődyek genealógiájában figyeltem fel arra, hogy ismeretlen okból néhány azonosító (206. és 207.) hiányzik a sorból, vagyis ténylegesen kevesebb (211) személyünk van, mint ami a dokumentum utolsó azonosítójából (213) következne. Ha az adatok feldolgozásakor egyszerűen csak sorra vesszük a bejegyzéseket, akkor ezek azonosítói és a táblázat megfelelő sorai idővel elcsúsznak egymáshoz képest, azaz rossz sorba fognak kerülni az adatok. Ezt nyilvánvalóan nem akarhatjuk, mert hibát okozhat.
A probléma itt úgy kerül kezelésre, hogy a bejegyzések kezdősorait tartalmazó bejegyzKezd vektor megfelelő pozíciójába – ha mondjuk a 206. azonosító hiányzik, akkor sorrendben a 206. helyre – beszúrásra kerül a nem létező bejegyzésre vonatkozóan egy speciális, jól felismerhető érték. (Amennyiben több azonosító hiányzik, akkor mindegyik helyére.) Ezzel számszakilag megfelelő mennyiségű bejegyzésünk lesz, a betoldásokat pedig a feldolgozáskor felismerjük és átugorjuk. A táblázatban eredetileg nem szereplő házastársak folytatólagosan új sorokat és ennek megfelelő azonosítókat kapnak.
A másik táblánk a hazassagok nevet viseli. A táblázat kezdetben üres, feltöltése a bejegyzések feldolgozásával párhuzamosan történik.
# A feldolgozandó nemzetség nevének megadása.
# A szöveges genealógiában szereplő helyesírásnak megfelelően, nemesi előnév nélkül kell beírni!
nemzNev <- "Széchényi"
# A szöveges genealógia beolvasása és a sor eleji felesleges szóközök eltávolítása.
# A letöltött fájlt be kell másolni a munkakönyvtárba.
# A fájl neve elvileg a fentebb megadott név ékezet nélküli változata. Ha nem az lenne, akkor át kell írni arra!
genSzoveg <- readLines(paste0(iconv(nemzNev, to="ASCII//TRANSLIT"), ".txt")) %>%
str_trim()
# A bejegyzések kezdősorainak meghatározása.
bejegyzKezd <- c(str_which(genSzoveg, START %R% digit(1,3) %R% DOT %R% SPC), length(genSzoveg)+1)
# A bejegyzések azonosítóinak meghatározása.
bejegyzID <- as.numeric(str_extract(genSzoveg[bejegyzKezd[1:length(bejegyzKezd)-1]], START %R% digit(1,3)))
# Az esetlegesen hiányzó bejegyzések kezelése. (Bővebben lásd a szöveges részben!)
if (length(bejegyzID) != length(first(bejegyzID):last(bejegyzID))) {
bejegyzKezd <- as.numeric()
for(i in first(bejegyzID):last(bejegyzID)){
x <- str_which(genSzoveg, START %R% i %R% DOT %R% SPC)
bejegyzKezd <- c(bejegyzKezd, ifelse(length(x) == 1, x, NA))
}
for (i in (length(bejegyzKezd)-1):1) {
if (is.na(bejegyzKezd[i])) {
bejegyzKezd[i] <- bejegyzKezd[i+1]
}
}
bejegyzKezd <- c(bejegyzKezd, length(genSzoveg)+1)
}
# Az egyének tábla létrehozása.
# Az ID mezőbe bekerülnek a nemzetség tagjainak azonosítói.
egyenek <- data.frame(ID = first(bejegyzID):last(bejegyzID),
nemzNev = as.character(NA),
kerNev = as.character(NA),
kerNevRovid = as.character(NA),
nem = as.character(NA),
apaID = as.numeric(9999),
anyaID = as.numeric(9999),
szulEv = as.numeric(NA),
szulHo = as.numeric(NA),
szulNap = as.numeric(NA),
szulPont = as.numeric(NA),
szulTelep = as.character(NA),
halEv = as.numeric(NA),
halHo = as.numeric(NA),
halNap = as.numeric(NA),
halPont = as.numeric(NA),
halTelep = as.character(NA))
# A házasságok tábla létrehozása.
hazassagok <- data.frame(hazID = as.numeric(),
ferjID = as.numeric(),
felesegID = as.numeric(),
hazEv = as.numeric(),
hazHo = as.numeric(),
hazNap = as.numeric(),
hazPont = as.numeric(),
hazTelep = as.character(),
elvEv = as.numeric(),
elvHo = as.numeric(),
elvNap = as.numeric(),
elvPont = as.numeric(),
elvTelep = as.character())A szöveges genealógia feldolgozása
A házastársi és a felmenő-leszármazotti kapcsolatok rögzítésének alapelveit korábban részletesen leírtam egy blogposztban. Ehhez természetesen mindenben tartom magam. Technikai szempontból a szöveges genealógiák feldolgozása úgy történik, hogy egyenként végigmegyünk az összes releváns bejegyzésen.
Ezekből először az adott illetőre vonatkozó személyi alapadatokat – név, nem, születési és halálozási időpontok, helyek – nyerjük ki.
Ezt követen sorra vesszük a házasságait, ha vannak ilyenek.
Az adott házastársnak létrehozunk egy új sort az egyének táblázatban és rögzítjük az ő személyes alapadatait is.
A házasságok táblában egymáshoz rendeljük a két személyt, majd kitöltjük a házasságkötés idejére és helyére, valamint az esetleges válásra vonatkozó adatokat.
Végül a házasságból származó gyermekek feldolgozása következik. Itt nyilván csak a fiági leszármazottakról van szó. Ők az azonosítójukkal már biztosan szerepelnek az egyének táblában, hiszen az apjukkal azonos nemzetségbe tartozván, maguk is részei a genealógiának. Velük mindössze annyi dolgunk van, hogy plusz (+) jel után feltüntetett azonosító alapján megkeressük őket és a megfelelő mezőkben rögzítjük az apjuk és az anyjuk azonosítóját. A rájuk vonatkozó többi adat kitöltése akkor történik, amikor sorra kerül az ő bejegyzésük.
Ha végeztünk az adott házassággal, akkor az illető további házasságai jönnek.
Amennyiben ezek elfogytak, akkor átugrunk a sorban következő bejegyzésre és minden kezdődik elölről.
Mindez addig ismétlődik, ameddig vannak feldolgozatlan bejegyzések.
A fenti gondolatmenet követhetősége érdekében az alábbi kódblokkba mindenhová bekommenteltem, hogy nagyjából mi történik az adott szakaszban.
# Sorban végigmegyünk az összes bejegyzésen.
for (i in first(bejegyzID):last(bejegyzID)) {
# A valóságban nem létező bejegyzések átugrása. (Bővebben lásd a szöveges részben!)
if (bejegyzKezd[i] == bejegyzKezd[i+1]) {
next
}
# Az adott bejegyzéshez tartozó összes sor kigyűjtése.
bejegyzSzoveg <- genSzoveg[bejegyzKezd[i]:(bejegyzKezd[i+1]-1)]
# A bejegyzés azon sorainak kigyűjtése, amelyben a személyes alapadatokat keressük.
# Az elejétől az első üres sorig tartó rész.
vizsgaltSzoveg <- paste(bejegyzSzoveg[1:(str_which(bejegyzSzoveg, START %R% "" %R% END)[1]-1)], collapse = " ") %>%
str_squish()
# A személyes alapadatok rögzítése az egyének táblába.
# A genealógiákban elvétve előforduló leányági leszármazottakat átugorjuk.
if (!str_detect(str_extract(vizsgaltSzoveg, mintaNemzNev), str_to_upper(nemzNev))) {
next
} else {
egyenek[i,"nemzNev"] <- nemzNev
}
egyenek[i,"kerNev"] <- str_extract(vizsgaltSzoveg, mintaKerNev) %>%
str_trim()
egyenek[i,"kerNevRovid"] <- unlist(str_split(egyenek[i,"kerNev"], or("-",SPC)))[1]
egyenek[i,"nem"] <- ifelse(str_detect(vizsgaltSzoveg, "daughter"), "nő", "férfi")
egyenek[i,c("szulEv","szulHo","szulNap","szulPont","szulTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, "born" %R% mintaIdopTelep))
egyenek[i,c("halEv","halHo","halNap","halPont","halTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, "died" %R% mintaIdopTelep))
# A házastársakkal és gyermekekkel kapcsolatos adatgyűjtés előkészítése.
# Az üres, a házasságokra és a gyermekekre utaló sorok sorszámának megjegyzése.
uresSorok <- str_which(bejegyzSzoveg, START %R% "" %R% END)
hazKezd <- str_which(bejegyzSzoveg, "married")
gyerekKezd <- str_which(bejegyzSzoveg, "Children")
# Sorban végigmegyünk az illető összes házasságán.
# Ezek a "married" tartalmú soroktól az ezt követő első üres sorig tartó részek.
for (j in hazKezd) {
# A bejegyzés azon sorainak kigyűjtése, amelyek az adott házasságra vonatkoznak.
vizsgaltSzoveg <- paste(bejegyzSzoveg[j:(uresSorok[uresSorok > j][1]-1)], collapse = " ") %>%
str_squish()
# A házastárs kap egy azonosítót és egy új sort az egyének táblában.
ujID <- nrow(egyenek)+1
egyenek[ujID,"ID"] <- ujID
# A házastárs személyes alapadatainak rögzítése az egyének táblába.
egyenek[ujID,"nemzNev"] <- str_extract(vizsgaltSzoveg, mintaNemzNev) %>%
str_to_lower() %>%
str_to_title()
if (is.na(egyenek[ujID,"nemzNev"])) {
egyenek[ujID,"nemzNev"] <- "Ismeretlen"
} else {
vizsgaltSzoveg <- str_replace_all(vizsgaltSzoveg, mintaNemzNev, "*")
}
egyenek[ujID,"kerNev"] <- str_extract(vizsgaltSzoveg, mintaKerNev) %>%
str_trim()
egyenek[ujID,"kerNevRovid"] <- unlist(str_split(egyenek[ujID,"kerNev"], or("-",SPC)))[1]
if (is.na(egyenek[ujID,"kerNev"])) {
egyenek[ujID,"kerNev"] <- "Ismeretlen"
egyenek[ujID,"kerNevRovid"] <- "Ismeretlen"
} else {
vizsgaltSzoveg <- str_replace(vizsgaltSzoveg, mintaKerNev, "*")
}
egyenek[ujID,c("apaID","anyaID")] <- rep(9999,2)
egyenek[ujID,c("szulEv","szulHo","szulNap","szulPont","szulTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, "born" %R% mintaIdopTelep))
egyenek[ujID,c("halEv","halHo","halNap","halPont","halTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, "died" %R% mintaIdopTelep))
# A házasságra vonatkozó adatok rögzítése a házasságok táblába.
ujHazID <- nrow(hazassagok)+1
hazassagok[ujHazID,"hazID"] <- ujHazID
if (egyenek[i,"nem"] == "férfi") {
egyenek[ujID,"nem"] <- "nő"
hazassagok[ujHazID,"ferjID"] <- egyenek[i,"ID"]
hazassagok[ujHazID,"felesegID"] <- ujID
} else {
egyenek[ujID,"nem"] <- "férfi"
hazassagok[ujHazID,"ferjID"] <- ujID
hazassagok[ujHazID,"felesegID"] <- egyenek[i,"ID"]
}
vizsgaltSzoveg <- str_replace_all(vizsgaltSzoveg, SPC %R% or("He","She"), "*")
hazassagok[ujHazID,c("hazEv","hazHo","hazNap","hazPont","hazTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, STAR %R% mintaIdopTelep))
if (!is.na(str_locate(vizsgaltSzoveg, "divorced")[,1])) {
hazassagok[ujHazID,c("elvEv","elvHo","elvNap","elvPont","elvTelep")] <- feldolgIdopTelep(str_match(vizsgaltSzoveg, "divorced" %R% mintaIdopTelep))
} else {
hazassagok[ujHazID,c("elvEv","elvHo","elvNap","elvPont","elvTelep")] <- c(rep(8888,4),"Nem vonatkozik rá")
}
# A házasságból származó gyermekek feldolgozása.
# Ezek a "Children" tartalmú soroktól az ezt követő első üres sorig tartó részek.
for (k in gyerekKezd) {
# Több házasság esetén az éppen aktuális feleséghez tartozó gyermekek sorainak meghatározása.
if ((str_extract(bejegyzSzoveg[k], mintaNemzNev) %in% str_to_upper(egyenek[ujID,"nemzNev"]) &
unlist(str_split(str_trim(str_extract(bejegyzSzoveg[k], mintaKerNev)), or("-",SPC)))[1] %in% egyenek[ujID,"kerNevRovid"]) |
egyenek[ujID,"nemzNev"] %in% "Ismeretlen") {
vizsgaltSzoveg <- paste(bejegyzSzoveg[(k+1):(uresSorok[uresSorok > k][1]-1)], collapse = " ") %>%
str_squish()
# A gyermekek azonosítóinak megszerzése, majd feldolgozása.
gyerekID <- as.numeric(str_remove(unlist(str_extract_all(vizsgaltSzoveg, PLUS %R% one_or_more(DGT))),PLUS))
if (egyenek[i,"nem"] == "férfi") {
egyenek[gyerekID,"apaID"] <- egyenek[i,"ID"]
egyenek[gyerekID,"anyaID"] <- ujID
} else {
egyenek[gyerekID,"apaID"] <- ujID
egyenek[gyerekID,"anyaID"] <- egyenek[i,"ID"]
}
}
}
}
}
# Az egyének tábla üresen maradt sorainak eltávolítása. (Nem létező bejegyzések, esetleges leányági leszármazottak.)
egyenek <- egyenek[complete.cases(egyenek),]A duplikált személyek eltávolítása
A fenti kóddal legenerált táblázatok duplán (többszörösen) jelen lévő embereket és házasságokat is tartalmazhatnak. Ez két dolog miatt van így:
Ugyanaz a személy a kérdéses nemzetség több tagjával is házasságra léphetett. A Széchényiek esetében ilyen volt Festetics Julianna (a genealógiában Júlia), aki előbb Széchényi József, majd az ő halála után Ferenc felesége lett. Andrássy Natália pedig a Széchényi Aladártól való válása után Bertalannal kötött házasságot. Itt tehát a kívülről jövő házastársak duplázódnak.
Az adott nemzetség tagjai egymás között is házasodhattak. Jelen esetben a Széchényi János és Julianna, illetve Széchényi Márton és Ditta párokat kell megemlíteni. Ők saját jogon eleve jelen vannak a genealógiában, később pedig bekerülnek házastársként is. Ugyanakkor házaspárként is duplázódnak.
A feladat az, hogy a többszörösen jelenlévő személyeket felismerjük, ezekből egyet megtartsunk, a többit pedig töröljük. Utóbbiak azonban szülőként és házastársként is jelen lehettek, ezért a törölt személyek azonosítóit korrigálni kell ezekben a szerepekben. Végül a többszörösen előforduló házasságkötések duplumait is törölni kell.
Azokat az illetőket tekintem többszörösen előfordulónak, akiknek a vezetékneve, az első keresztneve, valamint a születési és a halálozási éve megegyezik. Ez bizonyára nem ad tökéletes eredményt, ha viszont túlságosan árnyalt feltételeket állítunk be, akkor az esetleges adathiányok miatt nem lennének megtalálhatók az azonos személyek. Mivel csak tesztadatokról van szó, ezért megelégszem ennyivel. (Ha éles helyzetben csinálnám, akkor egy több lépcsőből álló félautomata közelítést alkalmaznék.) Egyébiránt a létrehozandó genealógiai kapcsolathálózat épségének védelme érdekében arra kell törekedni, hogy a lehetőségek közül azt az azonosítót tartsuk meg, amelyhez apa is csatlakozik. Házasságok esetében már sokkal egyértelműbb a helyzet: amelyik sorokban ugyanazt a férjet és feleséget találjuk, ott azonosság van. (Leszámítva persze azt az igencsak ritka esetet, amikor két személy másodszorra is házasságot köt.)
A duplumok feldolgozására egy külön eljárást írtam. Ez bemenetként az egyének és a házasságok táblákat várja, míg kiemenetként ezek korrigált változatát adja vissza. A végrehajtás során a konzolon tájékoztatót jelenít meg az ismétlődő személyekről és házasságokról.
feldolgDuplum <- function(feldolgEgynek,feldolgHazassagok) {
# Az egyének tábla sorainak egy egyedi azonosítót generál a név, a születési és a halálozási év alapján.
feldolgEgynek <- mutate(feldolgEgynek, sorID = paste0(nemzNev, " ", kerNevRovid, " (", szulEv, "-", halEv, ")"))
# Megállapítja és megszámolja a többszörös előfordulásokat az egyének táblában.
# Akiknek nem ismert a neve, vagy egyszerre hiányzik a születési és halálozási éve, azokat kizárjuk a vizsgálatból.
duplumok <- feldolgEgynek[,c("nemzNev", "szulEv", "halEv", "sorID")] %>%
filter(!(nemzNev == "Ismeretlen" | szulEv == 9999 & halEv == 9999)) %>%
group_by(sorID) %>%
summarise(db = n()) %>%
filter(db > 1) %>%
arrange(desc(db)) %>%
as.data.frame()
# Duplikált személyek azonosítóinak korrigálása az egyének és házasságok táblában.
torlendoID <- as.numeric()
duplumok$eltavolitottID <- as.character(NA)
duplumok$megtartottID <- as.numeric(NA)
for (i in 1:nrow(duplumok)) {
duplumID <- filter(feldolgEgynek, sorID %in% duplumok[i,"sorID"])
duplumID[duplumID == 9999] <- 999999
duplumID <- arrange(duplumID, apaID)$ID
duplumok[i,"megtartottID"] <- duplumID[1]
duplumok[i,"eltavolitottID"] <- paste(duplumID[2:length(duplumID)], collapse = " ")
for (j in 2:length(duplumID)) {
feldolgEgynek[feldolgEgynek$apaID == duplumID[j],"apaID"] <- duplumID[1]
feldolgEgynek[feldolgEgynek$anyaID == duplumID[j],"anyaID"] <- duplumID[1]
feldolgHazassagok[feldolgHazassagok$ferjID == duplumID[j],"ferjID"] <- duplumID[1]
feldolgHazassagok[feldolgHazassagok$felesegID == duplumID[j],"felesegID"] <- duplumID[1]
torlendoID <- c(torlendoID, duplumID[j])
}
}
# Statisztika kiíratása az ismétlődő személyekről.
cat("\nEGYÉNEK:\n")
print(duplumok)
# A duplikált egyének eltávolítása.
feldolgEgynek <- filter(feldolgEgynek, !(ID %in% torlendoID))
feldolgEgynek$sorID <- NULL
# A házasságok tábla duplumainak azonosítása, majd eltávolítása.
# A házasságok tábla sorainak egy egyedi azonosítót generál a férj és feleség azonosítója alapján.
feldolgHazassagok <- mutate(feldolgHazassagok, sorID = paste0(ferjID, "-", felesegID))
duplumok <- data.frame("eltavolitottHazassag" = feldolgHazassagok[duplicated(feldolgHazassagok$sorID),]$sorID)
# Statisztika kiíratása az ismétlődő házasságokról.
cat("\nHÁZASSÁGOK:\n")
print(duplumok)
# A duplikált házasságok eltávolítása.
feldolgHazassagok <- feldolgHazassagok[!duplicated(feldolgHazassagok$sorID),]
feldolgHazassagok$sorID <- NULL
# A végeredmény visszaadása.
return(list("egyenek" = feldolgEgynek, "hazassagok" = feldolgHazassagok))
}
# Az eljárás meghívása az egyének és házasságok táblával.
# A végrehajtás közben megjelenik a konzolon a statisztika.
genAdatok <- feldolgDuplum(egyenek, hazassagok)## EGYÉNEK:
## sorID db eltavolitottID megtartottID
## 1 Andrássy Natália (1864-1951) 2 430 419
## 2 Festetics Júlia (1753-1824) 2 362 359
## 3 Széchényi Ditta (1915-9999) 2 507 238
## 4 Széchényi János (1897-1969) 2 458 139
## 5 Széchényi Julianna (1900-9999) 2 432 165
## 6 Széchényi Márton (1909-1987) 2 532 210
##
## HÁZASSÁGOK:
## eltavolitottHazassag
## 1 139-165
## 2 210-238Az elkészült tesztadatok
A duplumok kiszűrése után véglegesnek tekinthető egyének és házasságok táblát a genAdatok$egyenek és a genAdatok$hazassagok utasítással érhetjük el a további feldolgozás során. Ezeket pontosvesszővel elválasztott CSV formátumban a write.csv2( genAdatok$egyenek, "egyenek.csv", row.names = F) és a write.csv2( genAdatok$hazassagok, "hazassagok.csv", row.names = F) utasításokkal le is tudjuk menteni a saját munkakönyvtárunkba.
Mivel ezeket a táblákat a továbbiakban a blogon megjelenő különböző módszerek kipróbálására szánom, ezért nem lenne életszerű az, ha az újabb olvasóknak mindig e blogposztban leírt kód lefuttatásával kellene kezdeniük a munkát. Éppen ezért letölthetővé teszem a végeredményt. Az alábbi két, pontosvesszővel elválasztott CSV fájl egyben tartalmazza a Batthyány, Erdődy, Esterházy, Festetics, Forgách, Károlyi, Pálffy és Széchényi nemzetségek adatait. A duplumok eltávolításakor is egyben kezeltem mindet. Az teszt-egyenek.csv 4237, a teszt-hazassagok.csv pedig 1740 rekordot tartalmaz. (Mellesleg itt megmutatkozik az R nyelv használatának az a nagy előnye, hogy ugyanazzal az algoritmussal nemcsak egy, hanem akárhány genealógiát le lehet bányászni. Megjegyzem azonban, hogy ezek összekötése olyan további módszertani problémákat is felvet, amelyekre itt nem tértem ki. A fenti kóddal önmagában egy-egy nemzetséget lehet kompletten megcsinálni.) Készítettem továbbá egy másik, az Access adatbáziskezelőben megnyitható változatot is. A teszt-adatbazis.accdb fájl adattartalma természetesen megegyezik az előbbiekkel, viszont a relációs adatbázisok logikájának megfelelően némileg átstrukturáltam az adatokat.
Végezetül ismételten és nyomatékosan hangsúlyozni szeretném, hogy senki ne vegye készpénznek e fájlok tartalmát, mert az eredeti forrásukból adódóan egészen biztosan vannak bennük hibás adatok és hiányosságok. Tesztelési célokra megfelelnek, tudományos adattárként nem!
Az elkészült tesztadatokat a későbbiekben számos feladatra használni tudjuk majd. Kedvcsinálóként álljon itt egy belőlük előállított hálózat, amelyen a színek az egyes nemzetségeket különböztetik meg. Szépen látszik, hogy a duplumok kiszűrése nyomán a Genealogie české šlechty honlapon még különálló fájlokban tárolt adatok összeálltak egy óriási hálózattá. Ugyanakkor az is látható, hogy van néhány kisebb, leszakadt darab, ami megerősíti az esetleges hibákról fentebb elmondottakat.
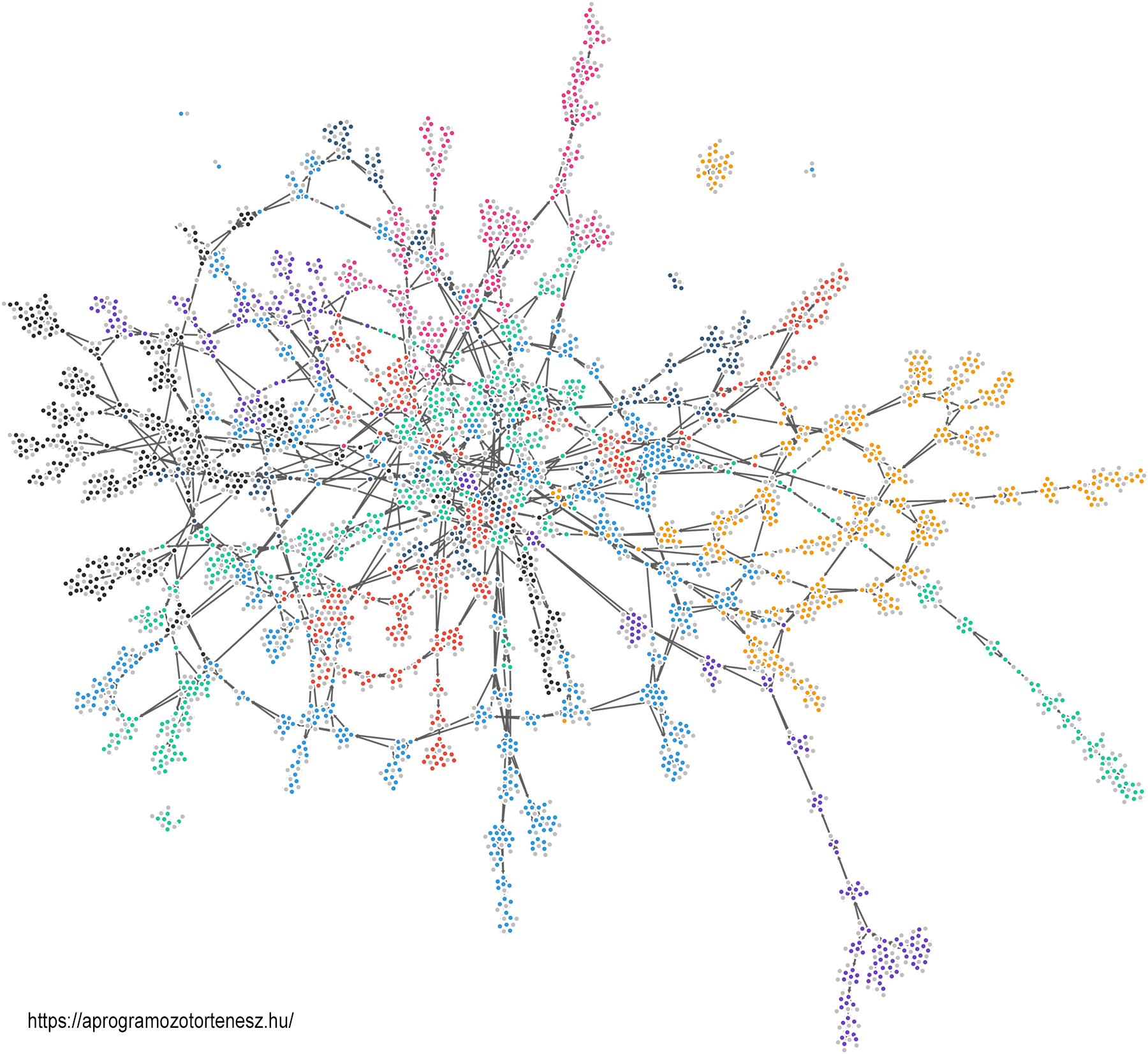
A tesztadatokból előállított genealógiai kapcsolathálózat (kattintásra nagyítható)