A genealógiai kapcsolathálózatok vizuális reprezentációja mögött mindig valamilyen adathalmaz áll. Ennek az adatbázisnak a kialakítására azért érdemes nagyobb figyelmet fordítani, mert ez jelentősen befolyásolja azt, hogy a későbbiekben mit tudunk kezdeni az összegyűjtött adatainkkal. Különböző adatbányászati módszerekkel persze bármilyen kusza adathalmazt fel lehet tárni. Sokkal jobban járunk azonban, ha eleve könnyen kezelhető formában rögzítjük az adatokat. Ebben a blogposztban azt mutatom be, hogy milyen struktúrával kell rendelkeznie egy genealógiai adatbázisnak ahhoz, hogy annak tartalmát később egyszerűen hálózattá tudjuk alakítani.
Az előző blogposztomban a genealógiai kapcsolathálózatokról elmondottak alapján bizonyára nem lesz újdonság senkinek, hogy az elkészítendő adatbázisban egyrészt a vizsgált embereket, másrészt pedig a köztük lévő kapcsolatokat akarjuk tárolni. Alapelv gyanánt mindenekelőtt szükséges leszögezni, hogy az egyedi ID-vel azonosított személyeket nem skatulyázhatjuk be eleve egy-egy szerepbe! Vagyis nincsenek külön szülők és külön gyermekek, külön házasságban élők és külön egyedülállók, hanem ezeket a szerepeket elvileg a vizsgált alapsokaság valamennyi tagja elfoglalhatja. Ahogy a való életben is így van ez. Ugyanaz a személy minden további nélkül lehet egyszerre gyermek, szülő és házastárs is. Ez csak attól függ, hogy kihez viszonyítjuk az illetőt. Az adatbázist úgy kell felépíteni, hogy abban minden személy csak egyszer forduljon elő, ezekből viszont bárkit, bármilyen szerepre, bármennyi alkalommal kiválaszthassunk.
A genealógiai kapcsolatok típusai
Egy hálózatban a kapcsolatokat úgy tudjuk definiálni, hogy megmondjuk, kik állnak ezek két végpontjában. A genealógiai hálózatban előforduló szerepek és kapcsolatok kombinálásával az alábbi szcenáriók képzelhetők el.
| “A” szerep | “B” szerep | A kapcsolat jellege | A kapcsolat típusa |
|---|---|---|---|
| apa | gyermek | leszármazási | egy a sokhoz |
| gyermek | apa | leszármazási | sok az egyhez |
| anya | gyermek | leszármazási | egy a sokhoz |
| gyermek | anya | leszármazási | sok az egyhez |
| férj | feleség | házassági | sok a sokhoz |
| feleség | férj | házassági | sok a sokhoz |
A táblázat szerint a leszármazási kapcsolatok az “egy a sokhoz” vagy “sok az egyhez”, a házasságok a “sok a sokhoz” típusba sorolhatók. Lényegét tekintve a kérdés itt az, hogy egy “A” szerepben lévő személyhez hány “B” szerepben lévő személy csatlakozhat. Így egy apának vagy anyának sok gyermeke lehet, vagy az utóbbiak felől nézve sok gyermek kötődhet ugyanahhoz az apához vagy anyához. A házasság pedig nemcsak a jelenlegi házastársak között teremthet összeköttetést, hanem azok múltbéli és jövendőbeli partnerei között is. Vagyis számolnunk kell annak az esetőségével, hogy mindketten több alkalommal voltak házasok az életük során.
A genealógiai hálózatot alkotó kapcsolatok típusaival azért érdemes tisztában lennünk, hogy megfelelő megoldást választhassunk ezen adatok tárolására.
A genealógiai adatbázis szerkezete
Sokan egyszerű táblázatokat használnak adatbázis gyanánt, ezek azonban nem igazán alkalmasak az ilyen jellegű feladatokra. Az egymáshoz kapcsolódó személyek rögzítésére kényszerűségből kitalált praktikák, mint az egy cellába írt több adat, a külön oszlop minden gyermeknek és házastársnak, vagy a sorok és a bennük lévő adatok egy részének megtöbbszörözése a gyakorlatban könnyen oda vezethet, hogy kezelhetetlenné és ezáltal hasznavehetetlenné válnak az adataink. Hiszen mire megyünk velük, ha végül nem tudjuk kinyerni és feldolgozni ezeket? Mindenesetre azt határozottan állíthatom, hogy az egyszerű táblázatoknál sokkalta jobb megoldást kínál a problémára az úgynevezett relációs adatbázisrendszer alkalmazása.
Egy relációs adatbázisban — függetlenül attól, hogy szoftveresen milyen platformon kerül megvalósításra — több különálló, de egymással kölcsönösen összefüggésbe hozható táblázatban kerülnek eltárolásra az adatok. Az egyes táblák közötti kapcsolatot az úgynevezett kulcsmezőkben szereplő értékek biztosítják. Ha genealógiai kapcsolatok rögzítésében gondolkodunk, akkor ezek a mezők (oszlopok) az egyes személyek egyedi ID-jeit tartalmazzák. Segítségükkel tehát a különböző táblákban tárolt rekordok (sorok) tartalmát össze lehet fésülni egymással. Vagyis ha két különálló tábla kulcsmezőjében megtalálható ugyanaz a konkrét ID, akkor az egyik tábla megfelelő rekordjai egyesíthetők a másik tábla megfelelő rekordjaival. Előfordulhat, hogy az egyik tábla egyetlen rekordjához a másik táblából több rekord is csatlakozik („egy a sokhoz” / „sok az egyhez” kapcsolat), illetve az is, hogy a két táblából kölcsönösen több rekord csatlakozik egymáshoz („sok a sokhoz” kapcsolat).
A továbbiakban egy konkrét példán keresztül mutatom be a genealógiai adatbázis általam ideálisnak tartott — gyakorlatban bevált — szerkezetét. (Itt csak mellékesen jegyzem meg, hogy egy valódi adatbázis ennél rendszerint sokkalta összetettebb felépítésű. Ennek részletekbe menő taglalása azonban túlmutatna e blogposzt keretin.) A példaként felhozott kapcsolathálózathoz a történelmi hátteret és az inspirációt a Széchenyi István családjáról Fónagy Zoltán által írt blogbejegyzés szolgáltatta. Itt egy úgynevezett mozaikcsaládról van szó, amelynek a lényege az, hogy a közös gyermekeken kívül a házasfelek egyikének-másikának voltak saját, korábban, más házastárstól született gyermekei is. Az így előálló kusza családi viszonyok kiváló alapanyagot jelentenek egy relációs adatbázis szerkezetének szemléltetéséhez.
EGYÉNEK TÁBLA
| ID | Név | Nem | ApaID | AnyaID | … |
|---|---|---|---|---|---|
| 257 | Széchenyi István | 1 | 9999 | 9999 | … |
| 2770 | Seilern Crescentia | 2 | 9999 | 9999 | … |
| 2784 | Széchényi Béla | 1 | 257 | 2770 | … |
| 2785 | Széchényi Ödön | 1 | 257 | 2770 | … |
| 2786 | Széchényi Júlia | 2 | 257 | 2770 | … |
| 2769 | Zichy Károly | 1 | 9999 | 9999 | … |
| 2778 | Esterházy Franciska | 2 | 9999 | 9999 | … |
| 2779 | Festetics Júlia | 2 | 9999 | 9999 | … |
| 2772 | Zichy Alfréd | 1 | 2769 | 2770 | … |
| 2774 | Zichy Géza | 1 | 2769 | 2770 | … |
| 2777 | Zichy Ilona | 2 | 2769 | 2770 | … |
| 2775 | Zichy Imre | 1 | 2769 | 2770 | … |
| 2771 | Zichy Karolina | 2 | 2769 | 2770 | … |
| 2773 | Zichy Mária | 2 | 2769 | 2770 | … |
| 2776 | Zichy Rudolf | 1 | 2769 | 2770 | … |
| 2780 | Zichy Ferenc | 1 | 2769 | 2778 | … |
| 513 | Zichy Pál | 1 | 2769 | 2778 | … |
| 195 | Zichy Béla | 1 | 2769 | 2779 | … |
| 2782 | Zichy Felicia | 2 | 2769 | 2779 | … |
| 23693 | Zichy György | 1 | 2769 | 2779 | … |
| 93 | Zichy Henrik | 1 | 2769 | 2779 | … |
| 2783 | Zichy Hermann | 1 | 2769 | 2779 | … |
| 2781 | Zichy Júlia | 2 | 2769 | 2779 | … |
| 512 | Zichy Ottó | 1 | 2769 | 2779 | … |
| 9999 | Ismeretlen | 9999 | 9999 | 9999 | … |
HÁZASSÁGOK TÁBLA
| HázasságID | FérjID | FeleségID | … |
|---|---|---|---|
| 5185 | 257 | 2770 | … |
| 2155 | 2769 | 2770 | … |
| 2153 | 2769 | 2778 | … |
| 2154 | 2769 | 2779 | … |
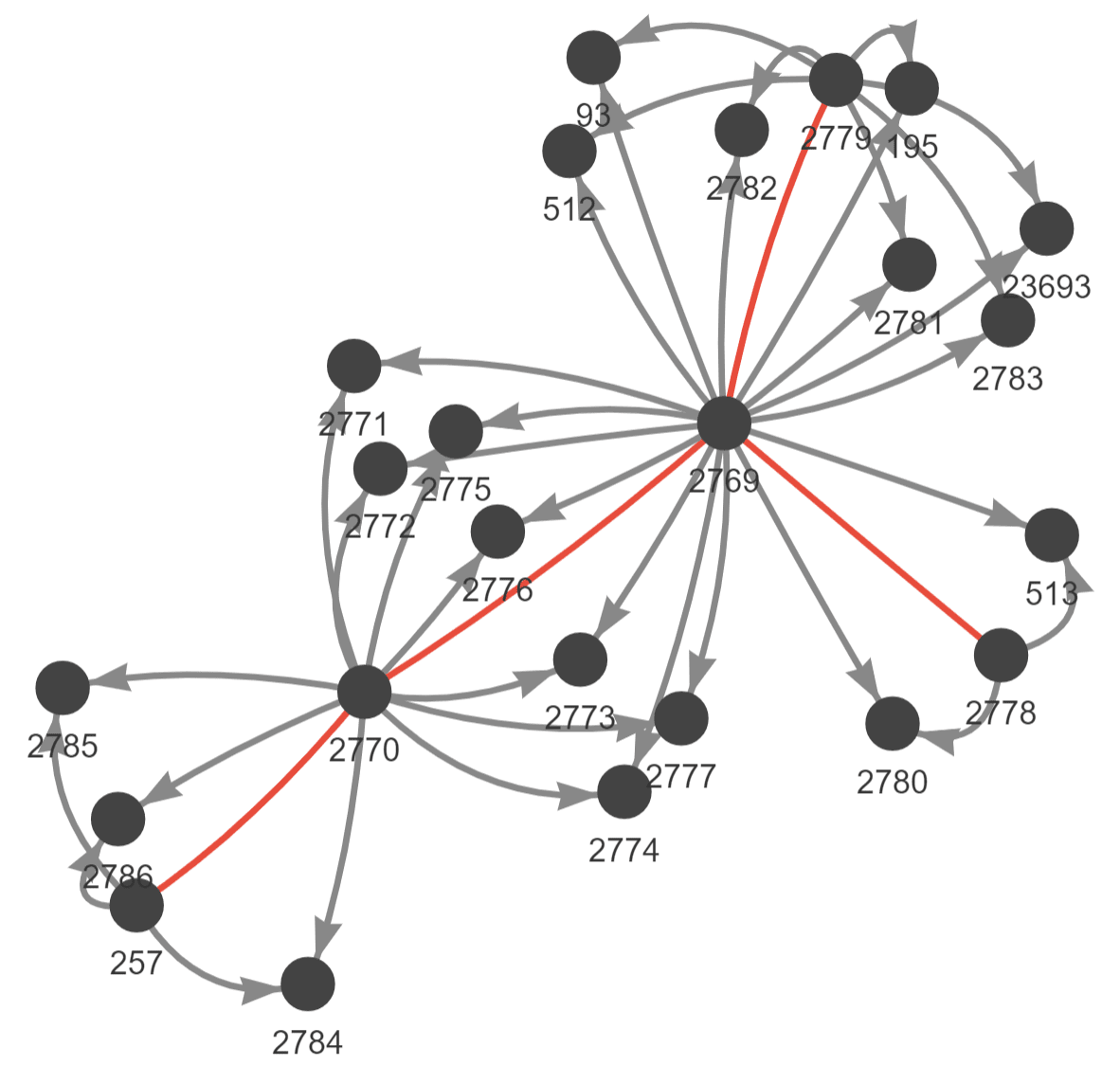
Széchenyi István mozaikcsaládja hálózatként ábrázolva (kattintásra nagyítható)
A fentiek szerint a genealógiai adatbázisnak minimálisan két táblából kell állnia. Az Egyének elnevezésű tábla rekordjai egy-egy személyt reprezentálnak, vagyis minden egyes sor egy önálló ID-vel azonosított ember adatait tartalmazza. Az ábrázolt tábla mezői az egyéni ID-ken kívül az illetők nevét és nemét foglalják magukban. Ezeken kívül a valóságban itt lenne a helye például a születési és halálozási idővel, hellyel kapcsolatos mezőknek is. (Ezeket jelképezi a … a táblázatokban.) Megoldást kellett találnunk viszont a szülő-gyermek kapcsolatok rögzítésére. Ahogy korábban már szó volt róla, ebben a rokonsági relációban az „egy a sokhoz” vagy a „sok az egyhez” kapcsolatban áll egymással a két érintett személy. Ezen a ponton tehát stratégiai döntést kell hozni az adattárolás mikéntjéről. Ha a szülők rekordjaihoz akarnánk hozzákötni a gyermekek rekordjait, akkor problémába ütköznénk, hiszen egy szülőhöz több gyermeket kellene csatlakoztatnunk. Ez is megoldható persze, de ehhez egy újabb tábla bevezetésére lenne szükség. Fordítva azonban minden további nélkül megtehetjük ezt, hiszen mindenkinek csak egy édesanyja és egy édesapja van. Vagyis a gyermekek rekordjaiból hivatkozni tudunk a szülőkre: az ApaID mezőbe az apa, az AnyaID mezőbe pedig az anya azonosítóját írjuk be. Ezt a műveletet nyilvánvalóan az utóbbiak esetében is elvégezhetjük, hiszen nekik is vannak, illetve voltak szüleik. Vagyis egy generációkon átívelő láncolatot hozhatunk létre a rekordokból. Ez már maga a rokonsági kapcsolathálózat!
A házasságok rögzítése a „sok a sokhoz” jellegből adódóan nem végezhető el az Egyének táblában. A megoldást itt a Házasságok tábla kialakítása jelenti. Ennek rekordjai egy-egy — szintén önállóan azonosított — házasságnak felelnek meg. Az összetartozó házasfelekre a FérjID és a FeleségID mezőkben hivatkozunk. Ez a megoldás lehetővé teszi azt, hogy az adatbázisunkban szereplő személyekből tetszőleges kombinációkban házaspárokat hozzunk létre.
A bemutatott konkrét példa főszereplője öt személy, akik bonyolult házassági nexusban állnak egymással. A hivatkozott blogposzt szerint Széchenyi István (257) 1836 elején, hosszas udvarlás után feleségül vette Seilern Crescentiát (2770). A grófnőnek azonban nem ez volt az első házassága. Előző férjét Zichy Károlynak (2769) hívták, akit korábban már két asszony is özvegyen hagyott. Az első feleségétől, Esterházy Franciskától (2778) kettő, a második nejétől, Festetics Júliától (2779) hét gyermeke született. A harmadik házasságából szintén hét utódja származott, emellett Seilern Crescentia Széchenyit is megajándékozta három gyermekkel. E családi viszonyoknak megfelelően tehát a Házasságok táblában négy, az Egyének táblában pedig huszonnégy rekordnak kell szerepelnie. A fentieken kívül elhelyeztem még egy 9999-es számú, Ismeretlen megnevezést viselő ID-t is az Egyének táblában. Ahogy látható, bizonyos emberek szüleiként erre hivatkozok. Azaz Széchenyi István és a másik négy kiemelt szereplő szülei ismeretlenként jelennek meg az adatbázisban. Ebből nem következik automatikusan az, hogy a kérdéses felmenők a genealógiai szakirodalom számára is ismeretlenek lennének. Jelen kontextusban ezzel az ID-vel az adathiányt nyomatékosítom. Arra utalok vele, hogy nem hanyagságból maradtak ki ezek a szülők az adatbázisból, hanem nagyon is tisztában vagyok a hiányukkal. A 9999-es érték egy saját kódolási konvenció eredménye, ami hasonló jelentéstartalommal az adatbázis egyéb szegmenseiben is felbukkan. Ehhez egy könnyen megjegyezhető és mással össze nem téveszthető értéket célszerű választani.
A fentiekben vázolt módszer tökéletesen alkalmas arra, hogy az így előállított adatbázisból könnyen kinyerjük azokat az adatokat, amelyeket a hálózatok elemzésére és vizualizálására szolgáló szoftverek bemenetként elfogadnak tőlünk. Ennek mikéntjét a későbbiekben egy önálló posztban fogom bemutatni.
Ha tudományos publikációban használná az itt leírtakat, akkor kérem, hogy hivatkozzon a blogposzt alapjául szolgáló munkámra: Ballabás Dániel: Családfákon innen és túl. Genealógiai kapcsolatok detektálása a hálózatok segítségével. In: Konferenciák, műhelybeszélgetések XVI. Hagyományos források, új megközelítések. A digitalizáció kínálta lehetőségek a történeti kutatásokban. Szerk. Ballabás Dániel. Eger, 2019.