A genealógiai adatok hálózatos struktúrája, az egyéneket és a házasságokat tartalmazó táblák adott felépítése elviekben bármely táblázatkezelőben megvalósítható lenne. Ennél azonban jóval többet kínál egy relációs adatbázis, amely az eredetileg különálló táblákat a köztük lévő kapcsolódási pontok figyelembevételével egyetlen egészként kezeli.
Amikor relációs adatbázisról beszélek, akkor nem egy konkrét alkalmazásra, hanem sokkal inkább egy adatszervezési elvre gondolok. Az egyes táblázatok közötti kapcsolat megteremtésére és kezelésére ugyanis számos szoftveres megoldás létezik. Én például az Accessben gyűjtöm az adatokat, mert a VBA nyelven programozható űrlapok igen kényelmes keretet biztosítanak ehhez. Az adatok feldolgozására, elemzésére és vizuális megjelenítésére viszont, annak sokoldalúsága miatt, legtöbbször már az R nyelvet használom. (Az Access és az R között viszonylag egyszerűen megvalósítható a közvetlen kapcsolat. Erről a következő blogposztban lesz majd szó.)
Az alábbiakban elsőként magáról a relációs adatstruktúráról beszélek, hogy értsük, mit is takar ez a valóságban és miért előnyös a számunkra. A poszt második felében pedig azt fogom gyakorlati példákon keresztül bemutatni, hogy miként lehet R nyelven létrehozni a táblázatok közötti relációs kapcsolatokat.
Az adatok hálózata
Egy relációs adatbázisrendszerben több, egymással kölcsönösen kapcsolatba hozható táblában helyezkednek el a rögzített adatok. Ez az adatstruktúra alapvető befolyással van arra, hogy milyen információkat tudunk kinyerni a forrásainkból. Hogy mindez jobban érthető legyen, az alábbi ábrán vizuálisan is megjelenítem a magyar főnemesség 1848 és 1918 közötti társadalomtörténetének és földbirtokviszonyainak feltárásához használt relációs adatbázisom szerkezetét.
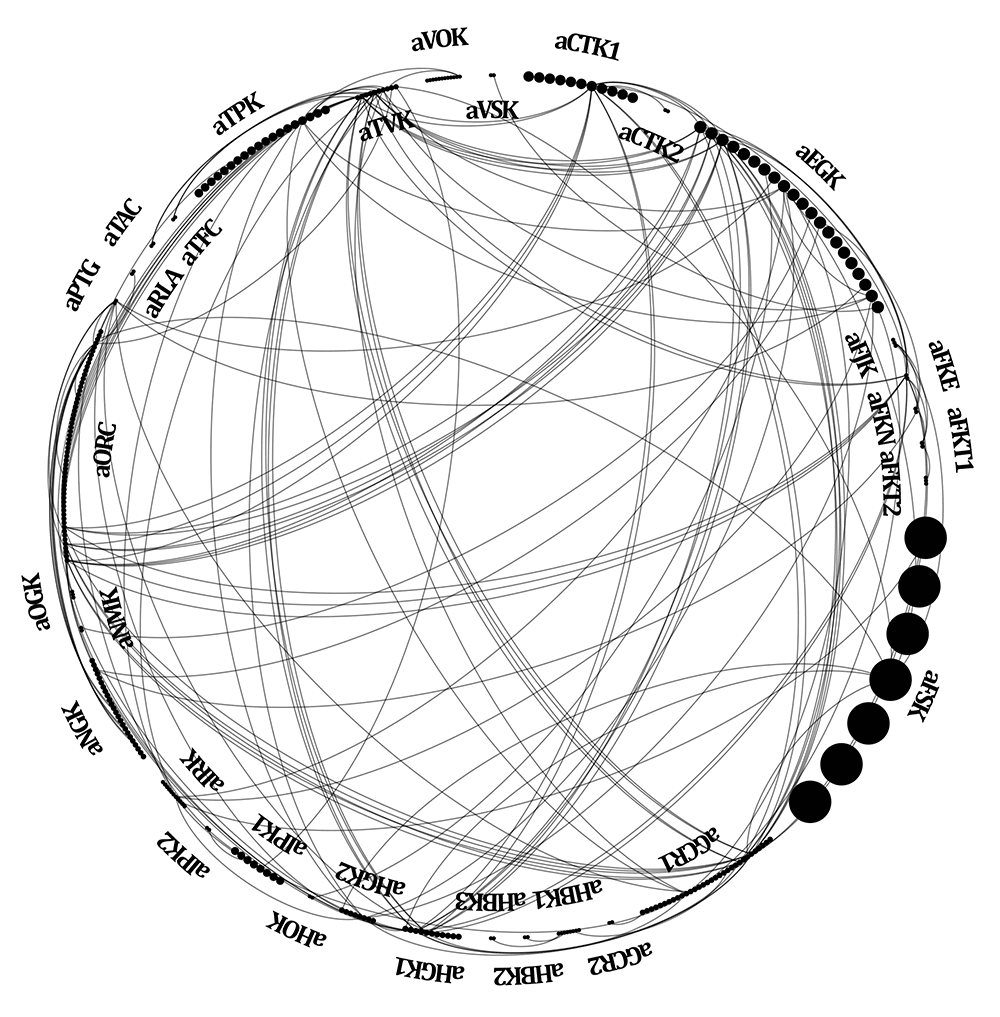
A saját adatbázisom belső kapcsolati hálója
Az ábrán látható kör kerülete mentén elhelyezkedő pontok egymástól elkülönülő, önálló névvel (rövidítéssel) ellátott csoportjai az adatbázis egy-egy tábláját szimbolizálják. Azaz összesen 32 táblába vannak szétosztva az adatok. Ezeken a csoportokon belül az egyes pontok a mezők (oszlopok) számát mutatják meg, ami itt táblánként 2 és 57 között változik. Végül a pontok nagysága az adott táblához tartozó rekordok (sorok) számával arányos. Minél nagyobbak, annál több rekord van a kérdéses táblában. A legtöbb (137250) rekorddal az a tábla rendelkezik, amelyben a begyűjtött adatok forrásait rögzítem (aFSK). Rögtön ezután következik az egyének alapadatait tároló tábla (aEGK). Ez 29498 rekordot tartalmaz, vagyis pillanatnyilag – az ábra elkészítésének idején – ennyi személyre vonatkozóan vannak adataim.
A relációs adatstruktúra lényege az, hogy az adatpontok között összefüggések létesíthetők. A rekordok szintjén az adott tábla minden mezője összefügg. Két rekord között pedig – bárhol is helyezkedjenek el az adatbázisban – akkor jön létre a kapcsolat, ha az egymással összekötött mezőikben („kulcsmező”) azonos érték szerepel.
A fenti ábrán látható linkek az adatbázis belső kapcsolatrendszerét mutatják meg. Összességében nézve tehát egy relációs adatbázis felfogható úgy is, mint az egymáshoz sokrétűen kapcsolódó adatok hálózata. Ebből következően aki ilyen adatbázist használ, az akkor is hálózatokat kutat, ha egyébként nincsen tudatában ennek.
A történész szemszögéből nézve ennek az a jelentősége, hogy a különböző forrásokból származó, az idők során innen-onnan összegyűjtögetett adatainkat végül egyetlen egészként kezelve tudjuk faggatni. (Feltéve persze, hogy a teljes kutatási tevékenységünket ugyanabban az adatbázisban folytatjuk.) Ha például megtalálok egy illetőt az országgyűlés főrendiházának almanachjában, akkor levéltári forrásokból hozzá tudom kapcsolni a tagságának pontos időintervallumát, egy internetes családkutató adatbázisból a születési adatait, ez kiegészíthető a gyászjelentésén szereplő halálozási adatokkal, különböző genealógiai munkákból pedig az illető szűkebb-tágabb rokonságával. De az utóbbiak között is lehetnek főrendiházi tagok vagy más fontos emberek, akiknek szintén vannak személyes alapadataik és rokonságuk… Vagyis a különálló, eltérő időpontokban keletkezett, különböző intézményekben őrzött források tartalmából egy sokrétűen összefüggő adathálózatot építhetünk. Ez az összekapcsolt adathalmaz nyilvánvalóan jóval többet ér annál, mint amennyit a felhasznált források egyenként, önmagukban állva adhatnak nekünk. Az adatok hálózata lehetővé teszi, hogy korábban kimutathatatlan összefüggéseket vagy ellentmondásokat tárjunk fel a feldolgozott történelmi forrásokban és azok között.
Relációs kapcsolatok létesítése R nyelven
Az elmondottak alapján tehát egy relációs adatstruktúrában több táblázatba vannak szétosztva az adatok, és ezen táblázatok között kapcsolatok létesíthetők. A táblák összekapcsolására azért van szükség, hogy alkalom adtán egyesíthessük azok adattartalmát. Vagyis egy olyan új táblázatot hozzunk létre, amelynek adatai eredetileg különböző táblázatokban szerepeltek.
Mivel a táblák egyesítését az Accessben is meg lehet csinálni (a műveletet lekérdezésnek nevezik), ezért adja magát a kérdés, hogy miért nem ott hajtjuk végre? Miért kell ehhez az R nyelv? Minderre azért lehet szükség, mert a táblázatok egyesítése általában nem a végcél, hanem egy köztes lépés a kutatás folyamatában. Amennyiben különböző számítások elvégzéséhez, vagy az adatok vizualizációjához tovább akarjuk hasznosítani ennek eredményét, akkor azt mindenképpen be kell töltenünk az R-be. Szerintem sokkal egyszerűbb, ha egyből itt kezdjük a munkát.
Az alábbiakban R nyelven (v4.0.3) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
A módszer alapjainak bemutatásához először létrehozok két egyszerű táblát és feltöltöm ezeket fiktív adatokkal. A véletlenszerűen legenerált karakterláncok előállításához a stringi csomag egyik funkcióját használom.
|
|
“A” tábla
| kulcs | adat |
|---|---|
| 1 | wbx7b8 |
| 2 | i76kic |
| 3 | vkvd7x |
| y2nzdf | |
| 4 | kfrxv5 |
| sfl79u | |
| 9999 | ebzfxp |
| 5 | gat1us |
| 1 | 9xnarx |
| 9999 | tutq2i |
“B” tábla
| kulcs | adat |
|---|---|
| 1 | xcsb29 |
| 2 | qyozzr |
| 3 | 91jui3 |
| 4 | wsmmgm |
| 5 | 172f7z |
| 6 | 3sc5x4 |
| 7 | kqczwj |
| 1 | 8cndv7 |
| 2 | nw1y2h |
| 9999 | ismeretlen |
Két tábla adatkeret egyesítésekor a kulcsmezők értékeit kell figyelni. Ahol ezek mindkét táblában megegyeznek, ott létrejön a kapcsolat és a releváns rekordok tartalma egymás mellé kerül a művelet eredményeként megkapott táblában. Ez az alapszituáció, amely az igényekhez képest finomítható. Az R nyelvre jellemző, hogy ugyanazt a feladatot többféle módon is végrehajthatjuk. Én itt a dplyr csomag megfelelő függvényeit hívom segítségül. Maga a kód szintaxisa nagyon egyszerű: x_join(A, B, by = "kulcs", suffix = c(".A",".B")) A kód elején látható x helyére az egyesítés típusa (inner, left, right, full, anti) írandó. Bővebben lásd lentebb. Az A és a B a két tábla neve, a by után pedig a kulcsmező elnevezése kerül. (Ha ezek neve történetesen nem lenne azonos a két táblában, akkor a by = c("kulcsA" = "kulcsB") szintaxist kellene használni!) Végül a suffix argumentum (nem kötelező) megadásával azt érhetjük el, hogy az eredményül kapott táblában felcímkéződnek az egyes mezők azok eredete szerint. Azaz jelen esetben a mezők neve után a .A vagy a .B utótag kerül, attól függően, hogy az adatok melyik táblából származnak.
|
|
Elöljáróban annyit jegyeznék meg még, hogy a táblázatok egyesítésekor érdemes nagyon körültekintően eljárni. Ugyan a fenti táblákat használva szemrevételezéssel is meg tudjuk majd mondani, hogy jól dolgoztunk-e, hiszen itt nagyon kicsi adatkészletekről van szó. A valóságban viszont sokszor lényegesen nagyobb táblázatokkal dolgozunk, alkalmasint nem csak kettővel, hanem egyszerre többel. Az ilyen esetekben ránézésre nem fog látszódni a hiba, ami természetesen tovább gördül a táblázatunkon alapuló további műveletekbe is. Ezért az egyesítés végrehajtása után mindig érdemes egy kicsit megállni és átgondolni a művelet eredményét.
inner join
|
|
| kulcs | adat.A | adat.B |
|---|---|---|
| 1 | wbx7b8 | xcsb29 |
| 1 | wbx7b8 | 8cndv7 |
| 2 | i76kic | qyozzr |
| 2 | i76kic | nw1y2h |
| 3 | vkvd7x | 91jui3 |
| 4 | kfrxv5 | wsmmgm |
| 9999 | ebzfxp | ismeretlen |
| 5 | gat1us | 172f7z |
| 1 | 9xnarx | xcsb29 |
| 1 | 9xnarx | 8cndv7 |
| 9999 | tutq2i | ismeretlen |
Az inner_join() típusú egyesítésnél azok a rekordok kerülnek be a végeredménybe, amelyeknél a kulcsmező adott értéke mindkét táblában megtalálható. (Az Accessben egyébként ez az alapértelmezett beállítás.) Jelen esetben a következők: 1, 2, 3, 4, 5, 9999. Ahogy fentebb látható, az “üres cella” csak az A, a 6 és a 7 csak a B táblában fordul elő. Az ezekhez tartozó rekordok tehát kimaradnak a végeredményből. Ugyanakkor vegyük észre azt is, hogy bizonyos kulcsok – itt az 1 és a 2 – többször is előfordulhatnak az adott táblán belül. Az ilyen esetekben a két tábla adatai kombinálódnak egymással a végeredményben. (Ez az alább bemutatott más típusú egyesítésekre is igaz!)
Az A és a B táblázatokban szerepel egy elsőre talán furcsának tűnő értékpár: a 9999 és az “ismeretlen”. Erről a kódolási konvencióról az előző blogposztomban már írtam. A dolog lényege az, hogy a feldolgozott forrásokból (egyelőre) megismerhetetlen adatokat a 9999-es értékkel helyettesítem, vagyis nem hagyom üresen a cellát. Ennek a gyakorlati jelentősége az ilyen lekérdezéseknél mutatkozik meg. Az A táblában üresen hagyott kulcshoz tartozó adatok ugyanis elvesztek a számunkra, ellenben a 9999-es kulcshoz tartozó adatok viszont ott szerepelnek az új táblánkban is. Az üresen maradt kulcs értékek tehát bizonyos lekérdezéseknél adatvesztéshez vezethetnek!
left join
|
|
| kulcs | adat.A | adat.B |
|---|---|---|
| 1 | wbx7b8 | xcsb29 |
| 1 | wbx7b8 | 8cndv7 |
| 2 | i76kic | qyozzr |
| 2 | i76kic | nw1y2h |
| 3 | vkvd7x | 91jui3 |
| y2nzdf | ||
| 4 | kfrxv5 | wsmmgm |
| sfl79u | ||
| 9999 | ebzfxp | ismeretlen |
| 5 | gat1us | 172f7z |
| 1 | 9xnarx | xcsb29 |
| 1 | 9xnarx | 8cndv7 |
| 9999 | tutq2i | ismeretlen |
Az left_join() típusú egyesítésnél a bal oldali (a kódban először megadott) tábla minden adata szerepel a végeredményben, a jobb oldali (másodjára megadott) táblából viszont csak azok a rekordok kerülnek be, ahol a kulcsmezők értékei megegyeznek.
right join
|
|
| kulcs | adat.A | adat.B |
|---|---|---|
| 1 | wbx7b8 | xcsb29 |
| 1 | wbx7b8 | 8cndv7 |
| 2 | i76kic | qyozzr |
| 2 | i76kic | nw1y2h |
| 3 | vkvd7x | 91jui3 |
| 4 | kfrxv5 | wsmmgm |
| 9999 | ebzfxp | ismeretlen |
| 5 | gat1us | 172f7z |
| 1 | 9xnarx | xcsb29 |
| 1 | 9xnarx | 8cndv7 |
| 9999 | tutq2i | ismeretlen |
| 6 | 3sc5x4 | |
| 7 | kqczwj |
Az right_join() típusú egyesítésnél pont ugyanaz történik, mint az előbb, csak a táblák sorrendje más. Itt a jobb oldali (másodjára megadott) táblából kerül be minden adat, míg a bal oldali (elsőként megadott) táblából csak azok, ahol a kulcsmezők értékei azonosak. (Ha felcserélnénk a kódban a táblákat, akkor a korábbival megegyező végeredményt kapnánk.)
full join
|
|
| kulcs | adat.A | adat.B |
|---|---|---|
| 1 | wbx7b8 | xcsb29 |
| 1 | wbx7b8 | 8cndv7 |
| 2 | i76kic | qyozzr |
| 2 | i76kic | nw1y2h |
| 3 | vkvd7x | 91jui3 |
| y2nzdf | ||
| 4 | kfrxv5 | wsmmgm |
| sfl79u | ||
| 9999 | ebzfxp | ismeretlen |
| 5 | gat1us | 172f7z |
| 1 | 9xnarx | xcsb29 |
| 1 | 9xnarx | 8cndv7 |
| 9999 | tutq2i | ismeretlen |
| 6 | 3sc5x4 | |
| 7 | kqczwj |
Az full_join() típusú egyesítésben mindkét táblából minden adat bekerül a végeredménybe. Ahol lehet, ott a megegyező kulcsok alapján egyesítésre kerülnek a két tábla rekordjai. Ahol nincs egyezés, ott üres cellák keletkeznek.
anti join
|
|
| kulcs | adat |
|---|---|
| y2nzdf | |
| sfl79u |
|
|
| kulcs | adat |
|---|---|
| 6 | 3sc5x4 |
| 7 | kqczwj |
Végezetül az anti_join() típusú egyesítéseknél a bal oldali (elsőként megadott) tábla azon rekordjait kapjuk meg, amelyeknél a kulcs mező értéke nem szerepel a jobb oldali (másodjára megadott) tábla kulcs mezejében. Ez tehát nem is egy valódi egyesítés, inkább csak egy speciális szűrésnek tekinthető. Értelemszerűen más eredményt kapunk, ha felcseréljük a bemeneti táblák sorrendjét.
A fentiekben megismertük a relációs adatbázisok belső szerkezetét és a táblák közötti kapcsolatok létesítésének alapjait R nyelven. A következő blogposztomban azt fogom bemutatni, hogy miként tudjuk kivarázsolni az adatokat egy Access adatbázisból.