Az alábbiakban azt fogom bemutatni, hogy az Access által alapértelmezettnek tekintett ACCDB, az Excel által preferált XLSX és a platformfüggetlen CSV formátumú adatállományokhoz hogyan tudunk hozzáférni az R-ből. Jelezni szeretném azonban, hogy mint az R programozási nyelv esetében annyi mindenben, itt is számos lehetőségből, több különböző csomagból választhatunk. Én természetesen azokat a megoldásokat mutatom be, amelyeket magam is kipróbáltam és rendszeresen használok. Nekem ezek jól beváltak. De ez nem azt jelenti, hogy kizárólag csak így lehet mindezt megcsinálni.
A kérdéses módszerek bemutatásához a korábban előállított tesztadatokat használom. Kezdésként hozzunk létre egy munkakönyvtárat és a teszt-adatbazis.accdb fájlt mentsük le abba!
Az Access adatbázishoz való hozzáférés
Az Access adatbáziskezelő ACCDB formátuma abból a szempontból (is) különbözik a táblázatos adatoktól, hogy ehhez nem tudunk közvetlenül hozzáférni. A teendő tehát nem pusztán annyi, hogy egy utasításban hivatkozunk a kérdéses állományra. Pontosabban hivatkoznunk kell rá, de az adatokhoz való hozzáférés közvetetten, az úgynevezett ODBC protokollon keresztül történik.
Az Access adatbázis használatához először regisztrálnunk kell azt a Windows ODBC adatforrás-felügyelőjében. (Itt feltételezem azt, hogy az olvasó az operációs rendszer, az R és az ODBC adatforrás-felügyelő esetében is egységesen a 64 vagy a 32 bites verziókat használja. Ezek keverése – amire egyébként nem látok racionális indokot – problémákat okozhat. Én magam 64 bites, magyar nyelvű Windows 10-en dolgozom.)
Az ODBC adatforrás-felügyelő beállítása
Az ODBC adatforrás-felügyelő beállításának lépései a következők:
-
A WIN+s billentyűkombinációval behívott keresőablakban (vagy a Start menü melleti kis nagyítóra kattintva) kezdjük el gépelni: ODBC-adatforrások. A találatok közül válasszuk ki a nekünk megfelelő 64 vagy 32 bites verziót.
-
Az ODBC adatforrás-felügyelő ablakban válasszuk a Felhasználói adatforrás fület, majd a Hozzáadás… gombot.
-
Az Új adatforrás létrehozása ablakban válasszuk ki a “Microsoft Access Driver (*.mdb, *.accdb)” illesztőprogramot.
-
A lényeg itt jön, az ODBC Microsoft Access beállítások ablakban:
-
Az Adatforrás neve mezőben kell megadnunk azt a nevet, amellyel az R-ből hivatkozni fogunk majd az adatbázisunkra. Ennek nem feltétlenül kell azonosnak lennie a fájl nevével, de persze nem is tilos. Célszerű egyetlen szóból álló, ékezet nélküli nevet választani.
-
A Kiválasztás… gombbal tudjuk megkeresni és megjelölni a konkrét adatbázist.
-
A Speciális… gomb alatt lehet megadni az adatbázisunk jelszavát, amennyiben rendelkezik azzal. A jelszót beállítani magában az adatbázisban kell, itt csak akkor van dolgunk, ha az jelszóval van védve. Ez egy nagyobb, értékesebb adatállománynál mindenképpen ajánlott. (A teszt adatbázis nincs jelszavazva.)
-
Az Egyebek>> gombbal előhívott felületen az Olvasásra jelölőnégyzetet bepipálva csak olvasható módban férünk majd hozzá az adatbázishoz. Aki szeretné elkerülni, hogy egy óvatlan pillanatban felülírja annak tartalmát, az használja így.
-
A fenti beállításokat elvégezve az ODBC adatforrás-felügyelő ablak Felhasználói adatforrás füle alatti listában immáron ott találjuk a saját adatbázisunk nevét is. Ezzel készen is vagyunk, az adatbázis elő van készítve a használatra. Az OK gombbal bezárhatjuk az ablakot.
Mindezt csak egyetlen alkalommal, az első használat előtt kell megtennünk. Ügyeljünk azonban arra, hogy a regisztrált adatbázist a későbbiekben ne mozdítsuk el a helyéről és ne nevezzük át. Ha ezt tennénk, akkor használhatatlanná válik a kapcsolat.
Az Access adatbázis csatlakoztatása az R-hez
Az alábbiakban R nyelven (v4.0.3) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
Az Access adatbázishoz való hozzáféréshez én a RODBC csomagot használom. Az ODBC adatforrás-felügyelőben az adatbázisunknak a “tesztadatbazis” nevet adtam. Így fogok tehát hivatkozni rá.
Innentől kezdve már könnyű dolgunk van. Betöltjük a RODBC csomagot, megteremtjük az adatbázissal való kapcsolatot, importáljuk a szükséges táblákat vagy egyéb műveleteket végzünk, majd zárjuk a kapcsolatot.
|
|
Az adatbázisban szereplő táblák kilistázása az sqlTables() függvénnyel történik. Ekkor alapból egy adatkeretet kapunk, sok irreleváns információval. Ráadásul az ebben felsorolt táblák között szerepel egy halom MSys… elnevezésű tétel is, amelyek az Access futtatásához szükségesek, de nekünk nem mondanak semmit. Ezektől meg szabadulnunk. Nekünk csak a tényleges táblák nevének felsorolása kell.
|
|
## [1] "egyenek" "hazassagok" "nemzetsegek" "telepulesek"
Most már tudjuk, hogy az adatbázisunkban négy tábla van és ismerjük is ezek nevét. Egy-egy konkrét táblát az sqlFetch() függvénnyel tudunk beimportálni az R-be. Ez az utasítás elején megadott változóba került. Jelen esetben az egyenek elnevezésű adatkeretnek 4238 rekordja és 17 mezője van. Ebből az első 10 rekord és 10 mező tartalma látható kinyomtatva a konzolra.
|
|
## # A tibble: 4,238 × 17
## ID nemzID kerNev kerNe…¹ nem apaID anyaID szulEv szulHo szulNap szulP…²
## <int> <int> <chr> <chr> <chr> <int> <int> <int> <int> <int> <int>
## 1 10001 1 Benedek Benedek férfi 9999 9999 9999 9999 9999 9999
## 2 10002 1 Tamás Tamás férfi 10001 10331 9999 9999 9999 9999
## 3 10003 1 Mihaly Mihaly férfi 10001 10331 1530 9999 9999 1
## 4 10004 1 István István férfi 10002 10332 9999 9999 9999 9999
## 5 10005 1 Márton Márton férfi 10003 10333 1560 9999 9999 1
## 6 10006 1 Pál Pál férfi 10004 10334 9999 9999 9999 9999
## 7 10007 1 János János férfi 10004 10334 9999 9999 9999 9999
## 8 10008 1 György György férfi 10004 10334 9999 9999 9999 9999
## 9 10009 1 Péter Péter férfi 10004 10334 9999 9999 9999 9999
## 10 10010 1 György György férfi 10005 10335 1592 9999 9999 1
## # … with 4,228 more rows, 6 more variables: szulTelepID <int>, halEv <int>,
## # halHo <int>, halNap <int>, halPont <int>, halTelepID <int>, and abbreviated
## # variable names ¹kerNevRovid, ²szulPont
Könnyen elképzelhető azonban, hogy az adatbázisunkban lévő táblákból nem akarunk válogatni, hanem egyszerre az összeset be szeretnénk importálni. Az alábbi utasítással ezt is megtehetjük. Ekkor az adatbázis minden táblája külön-külön, az eredeti elnevezésének megfelelő nevű adatkeretbe kerül.
|
|
## típus
## egyenek data.frame
## hazassagok data.frame
## nemzetsegek data.frame
## tablak character
## telepulesek data.frame
## tesztadatbazis RODBC
A RODBC csomag a fentiekhez képest egyéb lehetőségeket is kínál. Én azonban most megelégszem annyival, hogy az adatbázisban szereplő táblákat sikerült beimportálni az R-be. Ettől kezdve ugyanúgy lehet őket használni, mint bármely más adatkeretet. Például relációs kapcsolatokat létesíthetünk közöttük.
Mivel az importálást bármikor és bármennyi alkalommal meg lehet ismételni, ezért ennek ügyes használatával gyakorlatilag valós idejű hozzáférést kapunk az adatbázisunk tartalmához. Amit megváltoztatunk az Accessben, az a következő importálás után azonnal megjelenik az R-ben. Emellett fontos szempont az is, hogy nem az eredeti adatokkal dolgozunk, hanem azoknak csak egy másolatával. Így bármit is csinálunk velük az R-ben, az nem fogja eltorzítani az Accessben lévő adatkészletünket. (Az adatbázisba történő közvetlen visszaírással elővigyázatosságból nem próbálkoztam még. De erre az eddigiekben egyébként is csak elvétve lett volna szükségem.)
Hozzáférés az Excel fájlokhoz

A fentiekhez képest az Excelben készült adatállományok manipulálása sokkal egyszerűbb lesz. Annyiban mindenképpen, hogy ezt különösebb előkészítés nélkül, azonnal megtehetjük. Itt már érdekes lesz természetesen az Excel fájlokba történő írás is. Sőt, tulajdonképpen ezzel fogom kezdeni. Első körben az adatbázisból kivarázsolt táblákat írom ki XLSX formátumba, amihez az xlsx csomagot használom. Most már szükségünk lesz a munkakönyvtárunka is, ahová kimenthetjük, illetve ahonnan betölthetjük az adatainkat.
|
|
Az Excel fájlok írása
|
|
Egy adatkeret tartalmát a write.xlsx2() függvénnyel tudjuk lementeni az Excelnek megfelelő módon. (A write.xlsx() pontosan ugyanezt csinálja, csak érezhetően lassabban. Nagyobb tábláknál nem érdemes ezt használni. Jó kérdés persze, hogy miért használnánk bármihez is, ha a másik mindenhez megfelel. Úgy sejtem, hogy talán a visszafelé kompatibilitás miatt maradhatott bent a csomagban.) A függvény első paramétere az a változó, amely a lementeni szándékozott adatkeretet tartalmazza, ezen kívül meg kell adni a létrehozandó fájl nevét. Opcionálisan a munkalap neve is megadható. Ha ebből többet szándékozunk létrehozni, akkor az append = T (TRUE) paraméterrel azt érhetjük el, hogy egy azonos néven elmentett adatkészlet ne írja felül a már létezőt, hanem egy újabb munkalapot fűzzön hozzá ahhoz. (Ez csak akkor működik, ha meg van adva a munkalapok neve.) Végül a row.names = F (FALSE) paraméterrel megakadályozhatjuk, hogy az adatkészletünktől balra beszúrjon egy plusz oszlopot az adatkeret sorainak – legtöbbször be sem állított – nevével. A nevek hiányában sorszámokat kapnánk.
Előfordulhat azonban, hogy nem egyesével, hanem csoportosan akarjuk hozzáadni a fájlhoz munkalapokat. Mert sok van belőlük. Erre két lehetőséget is mutatok. Az első példában egy vektorban tárolva adom át a szükséges adatkeretek neveit, míg a másodikban egyenként soroltam fel ezeket. Mindkét példa ugyanazt a végeredményt adja: a tesztadatok3.xlsx fájlba az eredetileg az adatbázisból származó egyenek, hazassagok, nemzetsegek és telepulesek nevű táblák kerültek kiírásra az azonos nevű munkalapokra.
|
|
Az Excel fájlok beolvasása
Egy Excel fájl tartalmát a read.xlsx2() (read.xlsx()) függvénnyel tudjuk beolvasni az R-be. Ebben az esetben kötelező paraméterként meg kell adni vagy a munkalap nevét (sheetName), vagy annak sorszámát (sheetIndex). Ha egyiket sem szerepeltetjük az utasításban, akkor hibaüzenetet kapunk. Elsőként olvassuk vissza az imént kiírt tesztadatok3.xlsx fájl első vagy másképpen egyenek nevű munkalapját! Mindkét utasítás ugyanazt az eredményt adja. (Azaz a második felülírja az elsőt.)
|
|
Könnyen előfordulhat persze, hogy nem egyetlen (vagy néhány) munkalapot szeretnénk beolvasni, hanem egyszerre mindet. Ebben az esetben arról kell gondoskodni, hogy az Excel fájlban szereplő munkalapok tartalma külön-külön, azok elnevezésének megfelelő nevű adatkeretbe kerüljön. Az eljárás nagyon hasonlít ahhoz, mint amit fentebb, az adatbázis összes táblájának beolvasásánál mutattam.
|
|
## [1] "egyenek" "hazassagok" "nemzetsegek" "telepulesek"
|
|
## típus
## egyenek data.frame
## hazassagok data.frame
## munkalapok character
## nemzetsegek data.frame
## telepulesek data.frame
Egy alternatív megoldás az Excel fájlok beolvasására
A fenti utasításokat gyakran egy összetettebb algoritmus részeként kell alkalmaznunk. Ekkor nem tudjuk kikerülni a parancssoros felületet. Ha azonban csak egy-egy fájl beolvasására van szükségünk, akkor használhatjuk ehelyett az RStudio (v1.4.869) beépített importáló eszközét is. Ez a Fájl ➽ Import Dataset ➽ From Excel… menüben található. (Ennek hátterében a readxl csomag fut.) Én nem állítanám ugyan, hogy ez egyszerűbb vagy gyorsabb módja lenne az Excel fájlok beolvasásának, de végül is ez valahol ízlés kérdése. Szóval így is lehet.
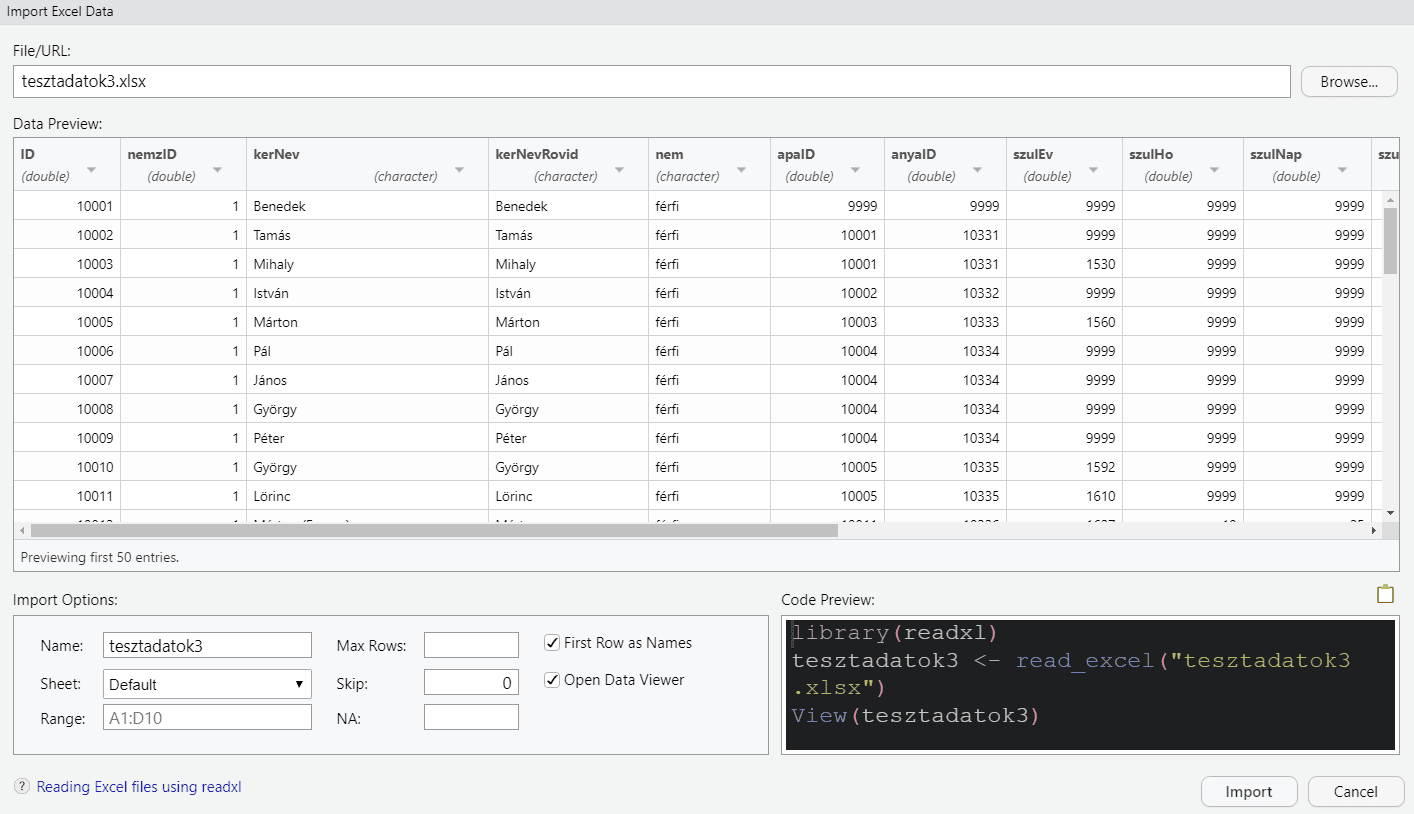
Excel fájl importálása az RStudio-ban
A CSV fájlok kezelése
A legvégére hagytam azt a formátumot, amelyik mind közül a legegyszerűbb felépítésű. A CSV egy angol betűszó, a comma-separated values rövidítése. Ez magyarul annyit tesz, hogy vesszővel elválasztott értékek. A CSV a táblázatos adatokat egy sima szövegfájlban tárolja. Ebben minden sor a táblázat egy-egy rekordjának (sorának) felel meg. Ezeken belül pedig vesszővel elválasztva sorakozik egymás után a mezők (oszlopok) tartalma. Értelemszerűen a vesszővel elválasztott értékek száma a szövegfájl minden sorában azonos. A CSV fájl egyetlen táblázatot tartalmaz, az Excellel szemben itt külön munkalapok nincsenek.
A vesszőt, mint szeparátort azonban nem kell szó szerint érteni. Annál is inkább, mert a Magyarországon általánosan használt tizedesvesszőt semmi nem különbözteti meg a CSV fájl mezőinek elválasztásához használt vesszőtől. Ez pedig hibát okozhat. Éppen ezért másfajta szeparátorok is alkalmazhatók, például a tabulátor vagy a pontosvessző. Én általában az utóbbi verziót szoktam használni. Mindezzel azért is érdemes tisztában lenni, mert a fájl .csv kiterjesztéséből ránézésre nem derül ki, hogy pontosan milyen elválasztóval készült. Lehet ilyen is, meg olyan is. Ezt úgy tudjuk a legegyszerűbben megállapítani, hogy a fájlt megnyitjuk a Windows Jegyzettömbjében.
Gyakorlatiasabb terepre evezve, mentsük ki a legutóbb beolvasottak közül az egyenek táblát pontosvesszővel elválasztott CSV formátumba. Ez a write.csv2() függvénnyel történik. (A sima write.csv() egy vesszővel tagolt fájlt hoz létre.) Az első paraméter a kimenteni szándékozott változó, majd a létrehozandó fájl neve következik. Az opcionális row.names = F paraméter, akárcsak az Excel esetében, a sorok elnevezését, illetve beszámozását akadályozza meg. (A CSV fájlok kezeléséhez szükséges utasítások helyből a rendelkezésünkre állnak, ezekhez nem kell külön csomagot betölteni.)
|
|
A CSV fájlok beolvasása ugyancsak egyszerű. A read.csv2() (read.csv()) függvényben mindössze a fájl nevét kell megadni. Hasznos opció lehet a header = F paraméter, amivel az közölhetjük az R-rel, hogy a táblázatunknak nincsen fejléce. (Alapból úgy tekinti, hogy van.) A skip = n paraméterrel pedig a tábla első n sorát hagyhatjuk ki a beolvasásból. Ez akkor jöhet jól, ha a CSV fájl elején valamilyen szöveges információ, figyelmeztetés szerepel. (Az Excelhez hasonlónan az RStudio Fájl menüjéből a szöveges fájlok importálására is lehetőségünk van.)
|
|
Végezetül az imént beolvasott CSV fájl első 10 (fejléccel együtt 11) sorát kinyomtatom előbb táblázatos formában, majd szöveges dokumentumként. Ahogy látható, mindkettő hátterében pontosan ugyanaz az adathalmaz áll. Szövegként kezelve azonban bepillantást nyerhetünk a CSV formátumú adattárolás technikai megvalósításába.
|
|
## # A tibble: 4,238 × 17
## ID nemzID kerNev kerNe…¹ nem apaID anyaID szulEv szulHo szulNap szulP…²
## <int> <int> <chr> <chr> <chr> <int> <int> <int> <int> <int> <int>
## 1 10001 1 Benedek Benedek férfi 9999 9999 9999 9999 9999 9999
## 2 10002 1 Tamás Tamás férfi 10001 10331 9999 9999 9999 9999
## 3 10003 1 Mihaly Mihaly férfi 10001 10331 1530 9999 9999 1
## 4 10004 1 István István férfi 10002 10332 9999 9999 9999 9999
## 5 10005 1 Márton Márton férfi 10003 10333 1560 9999 9999 1
## 6 10006 1 Pál Pál férfi 10004 10334 9999 9999 9999 9999
## 7 10007 1 János János férfi 10004 10334 9999 9999 9999 9999
## 8 10008 1 György György férfi 10004 10334 9999 9999 9999 9999
## 9 10009 1 Péter Péter férfi 10004 10334 9999 9999 9999 9999
## 10 10010 1 György György férfi 10005 10335 1592 9999 9999 1
## # … with 4,228 more rows, 6 more variables: szulTelepID <int>, halEv <int>,
## # halHo <int>, halNap <int>, halPont <int>, halTelepID <int>, and abbreviated
## # variable names ¹kerNevRovid, ²szulPont
## [1] "ID;nemzID;kerNev;kerNevRovid;nem;apaID;anyaID;szulEv;szulHo;szulNap;szulPont;szulTelepID;halEv;halHo;halNap;halPont;halTelepID"
## [2] "10001;1;Benedek;Benedek;férfi;9999;9999;9999;9999;9999;9999;9999;1542;9999;9999;4;9999"
## [3] "10002;1;Tamás;Tamás;férfi;10001;10331;9999;9999;9999;9999;9999;1571;9999;9999;4;9999"
## [4] "10003;1;Mihaly;Mihaly;férfi;10001;10331;1530;9999;9999;1;9999;1580;9999;9999;2;2"
## [5] "10004;1;István;István;férfi;10002;10332;9999;9999;9999;9999;9999;1618;9999;9999;4;9999"
## [6] "10005;1;Márton;Márton;férfi;10003;10333;1560;9999;9999;1;2;1629;9999;9999;3;3"
## [7] "10006;1;Pál;Pál;férfi;10004;10334;9999;9999;9999;9999;9999;1699;9999;9999;4;9999"
## [8] "10007;1;János;János;férfi;10004;10334;9999;9999;9999;9999;9999;1671;9999;9999;4;9999"
## [9] "10008;1;György;György;férfi;10004;10334;9999;9999;9999;9999;9999;1687;9999;9999;4;9999"
## [10] "10009;1;Péter;Péter;férfi;10004;10334;9999;9999;9999;9999;9999;1657;9999;9999;4;9999"
## [11] "10010;1;György;György;férfi;10005;10335;1592;9999;9999;1;2;1695;2;18;1;18"
A fentiekben igyekeztem minden fontosabb szempontra kitérni az ACCDB, az XLSX és a CSV fájlformátum R-rel történő kezelésével kapcsolatban. A fájlok kiírásához és beolvasásához használt függvények azonban olyan paramétereket, további finomhangolásra alkalmas beállítási lehetőségeket is tartalmazhatnak, amikről én itt nem ejtettem szót. Ezért érdemes lehet a kérdéses csomagok dokumentációját is áttanulmányozni.