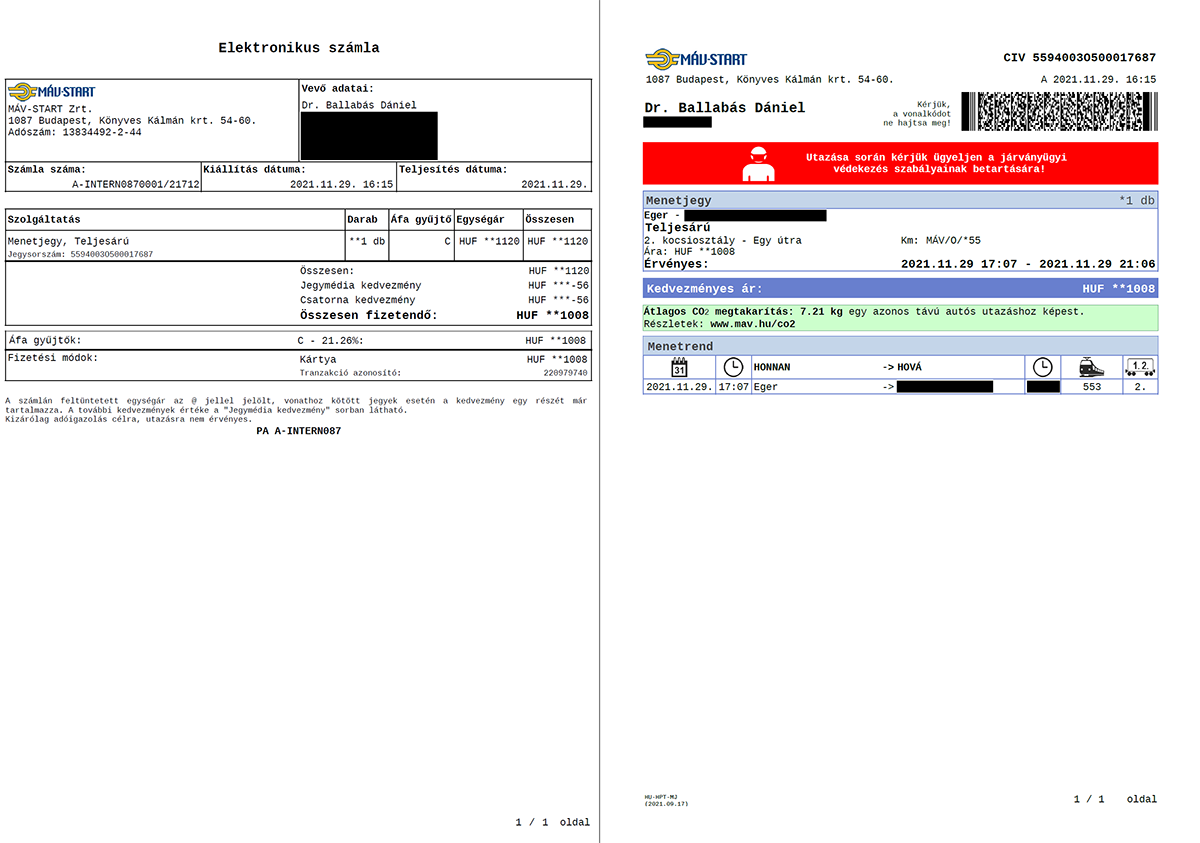
Mivel elég gyakran járok vonattal a munkahelyemre, ezért az oda-vissza utakat is beleszámítva akár kéttucatnyi alkalom is összejöhet egy-egy hónapban. És ehhez ugyanennyi számla társul. A jegyeket természetesen elektronikusan veszem meg és eszem ágában sem lenne kinyomtatni azokat. Csakhogy az utazások elszámolásához ezt kérik. Nincs apelláta.
A jegyek és számlák letöltésével járó munkát sajnos nem tudjuk megspórolni, ezt manuálisan kell továbbra is elvégezni a MÁV-START internetes jegyvásárlási felületén. Ezen túlmenően viszont a célom az, hogy ne darabonként kelljen kinyomtatni minden egyes jegyet és számlát, hanem egy algoritmus lefuttatása után kerüljön az összes letöltött fájl egyetlen PDF dokumentumba. Természetesen úgy, hogy az összetartozó jegyek és számlák az egymást követő oldalakon legyenek, dátum szerint sorba rendezve.
Ezt követően már annak sincs akadálya, hogy az egymáshoz tartozó jegyeket és számlákat egyetlen oldalra nyomtassuk ki. Így ezek összetűzésével sem kell bajlódnunk, és utazásonként egy lappal kevesebben kell nyomtatni. Hát nem szuper?
A művelet elvi alapja és végrehajtása
Az időrend szerinti sorba rendezés azon alapul majd, hogy a jegyeket és számlákat csak egyenként lehet letölteni, közben pedig telik az idő. Elsőként az utoljára megvásárolt jegyet, majd az ehhez tartozó számlát töltjük le, utána az eggyel korábbiakat és így tovább. A letöltött fájlok tehát különböző időpontokban kerülnek rá a számítógépünkre. Ha az utolsó módosítás dátuma alapján sorba rendezzük őket, akkor az egyúttal megfelel a vásárlás sorrendiségének is.
A letöltés mindig a legutóbbi vásárlással kezdődik, mert a rendszer ezt hozza ki elsőként. Én viszont az adott hónap legelső vásárlását szeretném a paksaméta tetején látni a nyomtatás után. Ennek érdekében az utolsó módosítás dátuma szerinti csökkenő sorrendbe kell rendezni a fájlokat, hiszen a legrégebben megvett jegyet töltjük le utoljára.
Egyéb tudnivaló nem nagyon van az alábbi rövid algoritmussal kapcsolatban. Illetve ami van, azt beleírtam a kódblokkba. (A futtatás során egy halom figyelmeztetés fogunk kapni arról, hogy a számlák jelszóval védettek. Az általunk végrehajtani kívánt művelethez azonban nem szükséges a jelszó, ezért az algoritmus minden további nélkül végrehajtódik.)
Hozzunk tehát létre egy munkakönyvtárat a számítógépünkön, mentsük bele a jegyeket és számlákat, aztán hajrá!
Az alábbiakban R nyelven (v4.1.2) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
A staplr csomag a Java telepítését vagy frissítését igényli a számítógépen, ennek hiányában nem fog futni!
|
|
Egy mindössze 6 soros kóddal meg is van oldva a probléma. És ezt is csak egyszer kellett megírni, ettől kezdve minden hónap elején használni tudom majd. Nem is értem, hogy miért nem így csináltam eddig.
Update
A blog Facebook oldalán a kollégáim részéről felmerült az az ötlet, hogy ha már ilyen szépen sikerült megoldani a jegyek összefűzését, akkor nem tudnám-e automatizálni az elszámoláshoz szükséges nyomtatvány kitöltését is? Természetesen megoldható a dolog. 😃
Mivel itt kétrétegű PDF dokumentumokkal van dolgunk, ezért azt fogom csinálni, hogy jegyekből kivonom azok szöveges rétegét, majd reguláris kifejezések segítségével kibányászom ebből az elszámoláshoz szükséges adatokat. Konkrétan: az utazás dátumát, a jegy árát, valamint az indulás helyét és a végállomás nevét. Mindezekből egy Excel táblázat készül, aminek tartalmát immáron egyszerűen be lehet másolni az elszámoló nyomtatványban lévő táblázatba.
Az adatokat a jegyekből fogjuk kibányászni. Ez technikailag azt jelenti, hogy a fentebb már időrendi sorba állított PDF dokumentumokból mindig a páros számúakat használjuk majd. Tudniillik a páratlanok a számlák. (Tehát az 1. dokumentum egy számla, a 2. jegy, a 3. egy számla, a 4. jegy…) Ehhez természetesen ügyelni kell arra, hogy először az adott utazáshoz tartozó jegyet töltsük le, és csak aztán a számlát. Ha nem így teszünk, akkor az algoritmus a számlákból próbál bányászni. Hibaüzenetet ugyan nem kapunk, de nem töltődik fel a táblázatunk.
Bár valószínűleg keveseket érint, de fontos tudnivaló továbbá, hogy az alábbi kód csak a magyar nyelven kiállított jegyekkel működik. Az angol nyelvű jegyekhez a reguláris kifejezéseken változtatni kell.
|
|
