Természetesen tisztában vagyok vele, hogy az interneten számos olyan oldal található, amelyek akár ingyen is lehetőséget kínálnak a PDF-ek manipulálására. Én azonban nem szívesen töltöm fel a saját dokumentumaimat egy számomra ismeretlen és ellenőrizhetetlen helyre, ahol semmi garancia nincsen arra, hogy nem őrzik meg és adják tovább azokat. És ugyanígy problémásnak érzem az interneten fellelhető, noname fejlesztőktől származó PDF-kezelő szoftverek telepítését is.
Bár nincs olyan csomag az R nyelvhez, amely minden szükséges funkciót egyben tartalmazna, de én összeszedegettem ezeket és az alábbiakban gyakorlati példákkal kiegészítve bemutatom a működésüket.
Előkészületek
A PDF dokumentumok manipulálásához használt függvények a következő csomagokból származnak: pdftools, staplr, tabulizer, magick, tesseract, png. Ezeket előre be fogjuk tölteni.
A staplr és a tesseract csomagok a Java telepítését vagy frissítését igényelhetik a számítógépen, ennek hiányában nem futnak. Erről bővebben az adott csomag saját oldalán lehet tájékozódni.
A mindennapi gyakorlatban, egy-egy konkrét feladat elvégzéséhez azonban nem feltétlenül van szükségünk az összes csomagra. Ezért az adott függvény származási helyének egyértelmű beazonosításához az első előfordulás alkalmával a csomag::függvény() formulát fogom használni a kódban. (A base csomag függvényei automatikusan betöltődnek.)
A csomagok betöltése mellett hozzunk létre egy munkakönyvtárat is a számítógépünkön, majd töltsük le ide a Hagyományos források, új megközelítések. A digitalizáció kínálta lehetőségek a történeti kutatásokban című kötetet az EKKE Történelemtudományi Intézetének honlapjáról. Ezen fogunk gyakorlatozni. A letöltést automatikusan elvégzi az alábbi kód.
Az alábbiakban R nyelven (v4.1.2) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
# A szükséges csomagok betöltése.
# A legelső használat előtt az install.packages("...") utasítással telepíteni
# kell ezeket. A ... helyére az adott csomag neve írandó.
library(pdftools)
library(staplr)
library(tabulizer)
library(magick)
library(tesseract)
library(png)
# Ide a saját munkakönyvtárunk elérését kell beírni!
setwd("C:/Munkakönyvtár")
# A könyv letöltése a munkakönyvtárba.
download.file("https://uni-eszterhazy.hu/api/media/file/ccb2c36cd341b7f271570dc96f039abd03093020", "digitalizacio.pdf", mode = "wb")Oldalak kivágása vagy eltávolítása a PDF dokumentumból
Viszonylag gyakran előforduló probléma, hogy egy publikációnk megjelenése után megkapjuk PDF-ben az egész kötetet. Ha szeretnénk a tanulmányunkat feltenni az internetre, például az Academia.edu oldalunkra, akkor el kell távolítani a kötetből a számunkra felesleges részeket.
A staplr::select_pages() függvény a megadott oldalakból önálló PDF fájlt készít. A függvénynek négy paramétere van:
| Paraméter | Magyarázat |
|---|---|
| selpages | az eltávolítandó oldalak (numerikus érték vagy vektor) |
| input_filepath | a bemeneti PDF dokumentum neve (karakterlánc) |
| output_filepath | a kimeneti PDF dokumentum neve (karakterlánc) |
| overwrite | a kimeneti PDF dokumentum felülírhatósága (logikai érték) |
A kivágandó oldalakat egy numerikus értékként kell megadni, illetve numerikus vektorban kell felsorolni. Azaz több oldalt vagy oldaltartományt is megadhatunk. Figyelni kell viszont arra, hogy a dokumentum lapjaira nyomtatott oldalszám nem feltétlenül egyezik meg az adott lap dokumentumon belüli sorszámával. Jelen esetben az Előszó például a 7. oldalon van a nyomtatott kötetben, de ez a 8. lap a PDF dokumentumban. (Hiszen az a borítót is tartalmazza.)
Amennyiben nem adunk meg kimeneti fájlt, akkor a rendszer rákérdez arra, hogy hová akarjuk az eredményt menteni. Ha bemeneti fájlt adjuk meg kimeneti fájlként, akkor minden figyelmeztetés nélkül felülíródik az. És ez minden, már létező fájlra igaz. Ezt a viselkedést az overwrite = FALSE paraméter hozzáadásával lehet megakadályozni.
Az alábbiakban a fentebb megadott kötetből kivágom és önálló fájlként elmentem az általam írt tanulmányt.
select_pages(selpages = 34:68, input_filepath = "digitalizacio.pdf", output_filepath = "digitalizacioFejezetBallabas.pdf")
Ha jól dolgoztunk, akkor a munkakönyvtárunkban keletkezett egy digitalizacioFejezetBallabas.pdf nevű dokumentum és ebben a “Családfákon innen és túl. Genealógiai kapcsolatok detektálása a hálózatok segítségével” című publikációm található.
Az elvégzett művelet inverzét hajtja végre a staplr::remove_pages() függvény. Ez a kötetből eltávolítja a megadott oldalakat és a kimeneti dokumentumba a maradékot menti el. A paraméterek és azok működése lényegében azonos a fentiekkel:
| Paraméter | Magyarázat |
|---|---|
| rmpages | az eltávolítandó oldalak (numerikus érték vagy vektor) |
| input_filepath | a bemeneti PDF dokumentum neve (karakterlánc) |
| output_filepath | a kimeneti PDF dokumentum neve (karakterlánc) |
| overwrite | a kimeneti PDF dokumentum felülírhatósága (logikai érték) |
remove_pages(rmpages = 34:68, input_filepath = "digitalizacio.pdf", output_filepath = "digitalizacioMaradek.pdf")
Ebben az esetben a digitalizacioMaradek.pdf dokumentumban csak a kötetben szereplő másik három tanulmány szerepel.
PDF dokumentumok összefűzése
Ugyancsak valós és gyakori probléma, hogy az ember le akar tölteni egy dokumentumot például a Hungaricana vagy az Arcanum Digitális Tudománytár elektronikus könyvtárakból, de a rendszerbe beépített korlátozások miatt ezt csak 25, illetve 50 oldalas egységekben tudja megtenni. A staplr::staple_pdf() függvény lehetőséget ad arra, hogy ezeket a különálló fájlokat egyetlen PDF dokumentumban egyesítsük.
A függvény paraméterei a következők:
| Paraméter | Magyarázat |
|---|---|
| input_directory | a bemeneti PDF dokumentumok könyvtára (karakterlánc) |
| input_files | a bemeneti PDF dokumentumok neve (karakter vektor) |
| output_filepath | a kimeneti PDF dokumentum neve (karakterlánc) |
| overwrite | a kimeneti PDF dokumentum felülírhatósága (logikai érték) |
Az input_directory és az input_files paraméterek alternatív lehetőséget kínálnak a feldolgozandó PDF dokumentumok megadására, vagyis csak az egyiket kell megadni.
Az előbbit akkor használjuk, ha a megadott könyvtárban lévő valamennyi .pdf kiterjesztésű fájlt fel akarjuk dolgozni. Amennyiben a munkakönyvtárunkról van szó, akkor az input_directory = getwd() alakban kell a paramétert megadni.
Ezzel szemben a másik paraméter lehetővé teszi, hogy karakter vektorként megadva konkretizáljuk a feldolgozandó PDF dokumentumokat. Ezt megtehetjük egyszerű felsorolással, például így: input_files = c("fájl1.pdf", "fájl2.pdf", "fájl3.pdf"). Sok fájl esetében azonban elég macerás feladat az egyenként felsorolás. Ha viszont szerencsénk van és a fájlok nevében felfedezhető valamilyen mintázat, akkor a base::grep() függvény segítségével indirekt módon is ki tudjuk választani ezeket: input_files = grep(pattern = "Szazadok_1867", x = dir(), value = TRUE). Ebben a példában azok a fájlok lesznek a bemeneti dokumentumok, amelyek megtalálhatók a munkakönyvtárunkban és a nevükben szerepel a “Szazadok_1867” szövegrész.
A maradék két paraméter működése a korábban elmondottaknak megfelelő.
Az alábbiakban először a már ismert módon szétbontom különálló tanulmányokra a kísérletezéshez használt kötetet, majd ezeket a PDF fájlokat összefűzöm egyetlen dokumentummá.
# A PDF dokumentum szétbontása különálló fájlokká.
# A digitalizacioFejezetBallabas.pdf már létezik a munkakönyvtárunkban!
select_pages(selpages = 10:33, input_filepath = "digitalizacio.pdf", output_filepath = "digitalizacioFejezetPap.pdf")
select_pages(selpages = 70:102, input_filepath = "digitalizacio.pdf", output_filepath = "digitalizacioFejezetNagy.pdf")
select_pages(selpages = 104:134, input_filepath = "digitalizacio.pdf", output_filepath = "digitalizacioFejezetRozsa.pdf")
# A fájlok összefűzése azok egyenkénti felsorolásával.
staple_pdf(input_files = c("digitalizacioFejezetPap.pdf",
"digitalizacioFejezetBallabas.pdf",
"digitalizacioFejezetNagy.pdf",
"digitalizacioFejezetRozsa.pdf"),
output_filepath = "digitalizacioEgyben1.pdf")
# A fájlok összefűzése a fájlnevekben lévő mintázat alapján.
staple_pdf(input_files = grep(pattern = "Fejezet", x = dir(), value = TRUE),
output_filepath = "digitalizacioEgyben2.pdf")
Az összefűzési műveletet kétféle módon hajtottam végre. Először manuálisan, egy karakter vektorban adtam meg az egyesítendő dokumentumokat, másodjára pedig a szükséges fájlok elnevezésében megtalálható mintázat – a “Fejezet” karakterlánc – alapján választottam ki azokat.
A digitalizacioEgyben1.pdf és a digitalizacioEgyben2.pdf fájloknak tehát oldalszámra egyformának kell lenniük. Ezt a pdftools::pdf_info("fájlnév.pdf")$pages kifejezéssel tudjuk ellenőrizni, amely egy PDF dokumentum oldalainak számát adja vissza.
pdf_info("digitalizacioEgyben1.pdf")$pages == pdf_info("digitalizacioEgyben2.pdf")$pages## [1] TRUE
Maga a fájl tartalma azonban nem teljesen egyforma, hiszen az első esetben az általam megadott sorrendben kerültek bele a publikációk, a másodjára viszont ábécérendben, a fájlok elnevezésének megfelelően.
A PDF dokumentum oldalainak elforgatása
Szkennelési hibából adódóan előfordulhat, hogy olyan PDF dokumentumot kapunk valahonnan, amelynek bizonyos oldalai a többihez képest el vannak forgatva. A staplr::rotate_pages() függvénnyel ezen is tudunk segíteni. Ennek paraméterei a következők:
| Paraméter | Magyarázat |
|---|---|
| rotatepages | az elforgatandó oldalak (numerikus érték vagy vektor) |
| page_rotation | az elforgatás szöge (numerikus érték) |
| input_filepath | a bemeneti PDF dokumentum neve (karakterlánc) |
| output_filepath | a kimeneti PDF dokumentum neve (karakterlánc) |
| overwrite | a kimeneti PDF dokumentum felülírhatósága (logikai érték) |
A kivágandó oldalakat egy numerikus értékként kell megadni, illetve numerikus vektorban kell felsorolni. Abban az esetben, ha egységesen minden páratlan vagy páros oldal hibás, akkor a base::seq() függvénnyel le is generálhatjuk a releváns oldalszámokat. Ekkor a rotatepages = seq(kezdet, pdf_info("bemenetiFájl.pdf")$pages, 2) módon megadott paraméterben a kezdet változó helyére páratlan oldalaknál 1, páros oldalaknál pedig 2 írandó.
A page_rotation paraméter értéke 0, 90, 180 vagy 270 lehet. Az oldalak a megadott szögben, az óramutató járásának megfelelő irányban fordulnak el.
A többi paraméter működése a korábban elmondottaknak mindenben megfelelő.
Mivel a kísérletezésre használt dokumentumunk minden oldala – természetesen – a helyes irányban áll, ezért ezt most elrontjuk és minden páros oldalt a feje tetejére állítunk. A változtatásokat a digitalizacioElforgatott.pdf nevű fájlba mentem el.
rotate_pages(rotatepages = seq(2, pdf_info("digitalizacio.pdf")$pages, 2),
page_rotation = 180,
input_filepath = "digitalizacio.pdf",
output_filepath = "digitalizacioElforgatott.pdf")
Ha a PDF dokumentum minden oldalát szeretnénk elforgatni, akkor a staplr::rotate_pdf() függvényt is használhatjuk. Ennek paraméterei azonosak az előbbivel, kivéve az első paramétert, amelyet ebben az esetben nem kell megadni.
PDF dokumentumokból képek, képekből PDF dokumentumok
A PDF dokumentumok használata sok esetben nagyon praktikus, de néha nem lehetséges. Ha például egy PDF-ként megkapott konferencia meghívót kell feltennem a munkahelyem Facebook-oldalára, akkor azt muszáj valamilyen képformátummá konvertálni. Ezt a pdftools::pdf_render_page() függvénnyel tudjuk megtenni, amelynek paraméterei az alábbiak:
| Paraméter | Magyarázat |
|---|---|
| a bemeneti PDF dokumentum neve (karakterlánc) | |
| page | a PDF-ből kivonandó oldal (numerikus érték) |
| dpi | a PDF-ből kivont kép felbontása (numerikus érték) |
Ezzel a függvénnyel egyszerre csak egy oldalt lehet kivonni a PDF dokumentumból, ezért ha nagyobb igényeink vannak, akkor be kell csomagolni egy kisebb algoritmusba. Itt az oldalak változóban egy numerikus vektorként kell felsorolni a képpé alakítandó oldalakat. A PDF dokumentumból kivont képeket a png::writePNG() függvénnyel PNG formátumban íratjuk ki a munkakönyvtárba. A fájlok az adott oldalszámnak megfelelően kerülnek elnevezésre.
# Példa: a PDF dokumentum felsorolt oldalai.
oldalak <- c(1,2,100,115:122,134)
# Példa: a PDF dokumentum összes oldala.
oldalak <- 1:pdf_info("digitalizacio.pdf")$pages
# A képek kivonása a PDF dokumentumból és PNG képként való elmentésük.
for (i in oldalak) {
print(i)
kep <- pdf_render_page(pdf = "digitalizacio.pdf",
page = i,
dpi = 300)
writePNG(image = kep, target = paste0(i, ".png"))
}
(A képek kivonását egyébként a tabulizer::make_thumbnails() függvénnyel is megtehetnénk, amihez nem kellene plusz algoritmust sem írni. Ez azonban a tapasztalataim szerint zabálja a memóriát és menet közben gyakran lefagy, megszakad. Én nem ajánlom a használatát.)
A fentiek mellett a képekkel való munka fordítva is elképzelhető, amikor képekből akarunk PDF dokumentumot készíteni. Természetesen erre is van megoldás. Itt a magick::image_read() függvénnyel beolvassuk a képeket egy speciális vektorba. Ezt követően pedig a magick::image_write() függvénnyel kiírjuk a képeket egy PDF dokumentumba.
A magick::image_read() függvény általam használt paramétere:
| Paraméter | Magyarázat |
|---|---|
| path | a bemeneti PNG képek neve (karakterlánc vagy karakter vektor) |
Jelen esetben a munkakönyvtárunkban lévő valamennyi .png kiterjesztésű képet fel kívánjuk használni, és természetesen az oldalszámoknak megfelelő sorrendben akarjuk ezeket szerepeltetni a létrehozandó PDF-ben.
A probléma ott van, hogy bár számokat látunk a képfájlok elnevezésében, a fájlnevekhez azonban a “.png” kiterjesztés is ugyanúgy hozzátartozik, vagyis itt valójában karakterláncokról van szó. (1.png, 2.png, 3.png, …) Márpedig a karakteresen megadott számok nagyon másként rendeződnek sorba, mint ugyanazok numerikus formátumban:
sort(as.character(1:20))## [1] "1" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "2" "20" "3" "4" "5" "6" "7" "8" "9"sort(as.numeric(1:20))## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Amennyiben nem fordítunk figyelmet a fájlok beolvasásának helyes sorrendjére, akkor a létrehozott PDF dokumentumban összevissza jelennek majd meg az oldalak. A mi esetünkben a path = paste0(grep(pattern = "png", x = dir()), sep = ".png") módon kell megadni a fenti paramétert. Erről a mintaillesztéses eljárásról korábban már volt szó. Most a közös mintázatot a kérdéses fájlok elnevezésében szereplő “png” karakterlánc adja.
A gyakorlásra használt fájloktól elvonatkoztatva viszont minden további nélkül előfordulhat, hogy megbízunk a fájlok elnevezésében. Ekkor a path = grep(pattern = "png", x = dir(), value = TRUE) módon megadott paraméterrel egyszerűen csak beolvassuk a munkakönyvtárban lévő összes .png kiterjesztésű képet.
A magick::image_write() függvény általam használt paraméterei:
| Paraméter | Magyarázat |
|---|---|
| image | a konvertálandó képek (magick image vektor) |
| path | a létrehozandó dokumentum elnevezése (karakterlánc) |
| format | a létrehozandó dokumentum típusa (karakterlánc) |
Az elsőként megadott függvény kimenete lesz tehát a második függvény bemenete, amelyből a megadott néven előállítja a PDF típusú dokumentumot.
Nézzünk erre is egy példát! Most a digitalizacio.pdf dokumentumból korábban kivont képeket visszakonvertáljuk egy digitalizacioKepekbol.pdf nevű dokumentummá.
kepek <- image_read(path = paste0(grep(pattern = "png", x = dir()), sep = ".png"))
image_write(image = kepek, path = "digitalizacioKepekbol.pdf", format = "pdf")
Meg kell még említenem, hogy a magick csomag a számítógép háttértárát is felhasználja memóriaként. A feladat elvégeztével az ideiglenesen létrehozott fájlok elvileg törlődnek onnan. Ha viszont valami miatt félbeszakad a művelet, mert például elfogy a lemezterület, akkor ezek a fájlok megmaradnak és adott esetben több gigabájtnyi tárhelyet is elfoglalhatnak. Ha úgy adódik, hogy manuálisan kell eltávolítanunk ezeket, akkor a base::tempdir() függvénnyel találhatjuk meg a helyüket a merevlemezen.
A PDF dokumentumok szöveges rétege
Az úgynevezett kétrétegű PDF dokumentumok az eredeti kiadvány vizuális látványvilágának megőrzése mellett kereshető és másolható szöveget is tartalmaznak. Ezt a szöveges tartalmat a pdftools::pdf_text() függvénnyel tudjuk kinyerni a dokumentumból. Ennek egyetlen paramétere maga a fájl neve.
Alább a digitalizacio.pdf dokumentumból kinyert szöveges tartalmat a szoveg nevű karakteres vektorba mentem el. Ennek a vektornak annyi eleme lesz, ahány oldala van a dokumentumunknak. Példaként a 34. oldalon lévő szöveget nézzük meg.
# A dokumentum szöveges tartalmának kinyerése egy vektorba.
szoveg <- pdf_text("digitalizacio.pdf")
# A vektor 34 elemének kinyomtatása.
cat(szoveg[34])## Ballabás Dániel
##
##
## Családfákon innen és túl.
## Genealógiai kapcsolatok detektálása
## a hálózatok segítségével*
##
##
##
## A történelmi problémáknak a hálózattudomány eszközeivel és módszertanával törté-
## nő megközelítése egyelőre nem tartozik a hazai történészek által különösebben pre-
## ferált tevékenységek közé.1 Noha maga a hálózattudomány (jelentős matematikai és
## szociológiai előzményekre támaszkodva) csak a 21. század elején jelent meg az önálló
## diszciplínák sorában,2 a hálózatként leírható jelenségekkel való tudományos igényű
## foglalatoskodás ennél sokkal régebbi keletű. Amikor például Nagy Iván a Magyaror-
## szág családai czímerekkel és nemzékrendi táblákkal címet viselő, 1857 és 1868 között
## 13 kötetben megjelent munkáját közreadta, egészen biztosan nem gondolt arra, hogy
## ő valójában hálózatokkal foglalkozik. Pedig lényegében erről volt szó. Ahogy az első
## kötet bevezető soraiban olvashatjuk: „Nemzetünk történelméhez adni kalauzt, mely
## a szerepelt személyek eredetével, családi összeköttetéseivel ismertet meg, – főczélja
## e gyüjteménynek.”3 Tudniillik a hálózat egy olyan rendszer, amely csomópontokból
## és a köztük lévő kapcsolatokból (linkekből) áll.4 Nagy Iván idézett munkája esetében
## a csomópontokat a személyek, míg a kapcsolatokat a horizontális és vertikális családi
## összeköttetések jelentik. Ezek alapján a kötetben szereplő családfák tökéletesen leír-
## hatók a hálózattudomány számára értelmezhető módon. Mindez Kempelen Béla és
## Gudenus János József sokat forgatott kézikönyveire, valamint az elmúlt másfél évszá-
## zadban napvilágot látott számtalan egyéb genealógiára is ugyanígy igaz. Azaz a háló-
## zatok jelenléte egyáltalán nem újdonság a történelmi tárgyú munkákban, csak éppen
## nem így nevezték őket. A mai kor történészeire vár a feladat, hogy a hálózatként leírha-
## tó struktúrákat felismerjék, és kutatásaikban (újra)hasznosítsák azokat. Megjegyzendő
##
## * A tanulmány elkészítését az EFOP-3.6.1-16-2016-00001 „Kutatási kapacitások és szolgáltatások
## komplex fejlesztése az Eszterházy Károly Egyetemen” című pályázat támogatta. Ugyancsak köszönöm
## az NKFIH 112429 „A dualizmus kori magyar országgyűlések tagjainak feltárása és társadalomtörténe-
## ti elemzése” címet viselő pályázatának támogatását.
## 1 A kivételek között említhető: Bozsonyi–Horváth–Kmetty 2012, Horváth 2013, Horváth 2017, Markó
## 2018, Nagy 2019, Szántay 2014, Pap 2016, Rab 2017, Tózsa-Rigó 2014. Elméleti megközelítésként:
## Brandt 2003, Kovács 2012.
## 2 Barabási 2016: 40.
## 3 Nagy 1857–1868: I. kötet előszó, oldalszám nélkül.
## 4 Barabási 2016: 60.
##
##
## 33
Amint látható, a mintaként kiválasztott oldal szövegét szépen megkaptuk a dokumentumból. A helyzet azonban sajnos nem ilyen egyszerű. Az Adobe cég által kifejlesztett és mostanra szabvánnyá vált formátum célja ugyanis elsősorban a dokumentumok hordozhatóságának a megvalósítása. A PDF mozaikszó pontosan ezt jelenti: Portable Document Format.
A lényeg tehát az, hogy minden számítógépen pontosan ugyanúgy nézzen ki az adott dokumentum. A háttérben lévő szöveges réteg tördelése viszont már nem feltétlenül alkalmazkodik a látható réteg tartalmához. Emberként nem kérdéses például, hogy az egymás melletti két hasábban szereplő szövegrészeket milyen sorrendben kell olvasni. Ezzel szemben egy PDF dokumentum szöveges rétegében könnyen előfordulhat, hogy az első hasábban megkezdett sor néhány szóköz után a második hasáb tartalmával folytatódik. És ugyanígy érzékeny pontnak számít a táblázatokhoz tartozó szövegrészek egy egységként való kezelése is.
Az említett problémák szerencsés esetben szövegbányászati módszerekkel és egyéb trükkös megoldásokkal kezelhetők. A táblázatok kinyerésére viszont kész megoldást kínál a tabulizer::extract_tables() függvény. Ennek általam használt paraméterei a következők:
| Paraméter | Magyarázat |
|---|---|
| file | a bemeneti PDF dokumentum neve (karakterlánc) |
| pages | a táblázatot tartalmazó oldalak (numerikus érték vagy vektor) |
| encoding | a szöveg karakterkódolása (karakterlánc) |
| output | a kimeneti adatok formátuma (karakterlánc) |
A cél az lenne, hogy egy adatkeretben, vagyis elemezhető formátumban kapjuk meg a táblázat tartalmát. A kérdéses függvény egyszerre több oldallal is elboldogul. A felismert és a dokumentumból kinyert táblázatok egy listába kerülnek.
Nézzük meg, hogyan boldogul a függvény a digitalizacio.pdf 56. (55.) oldalán található táblázattal.
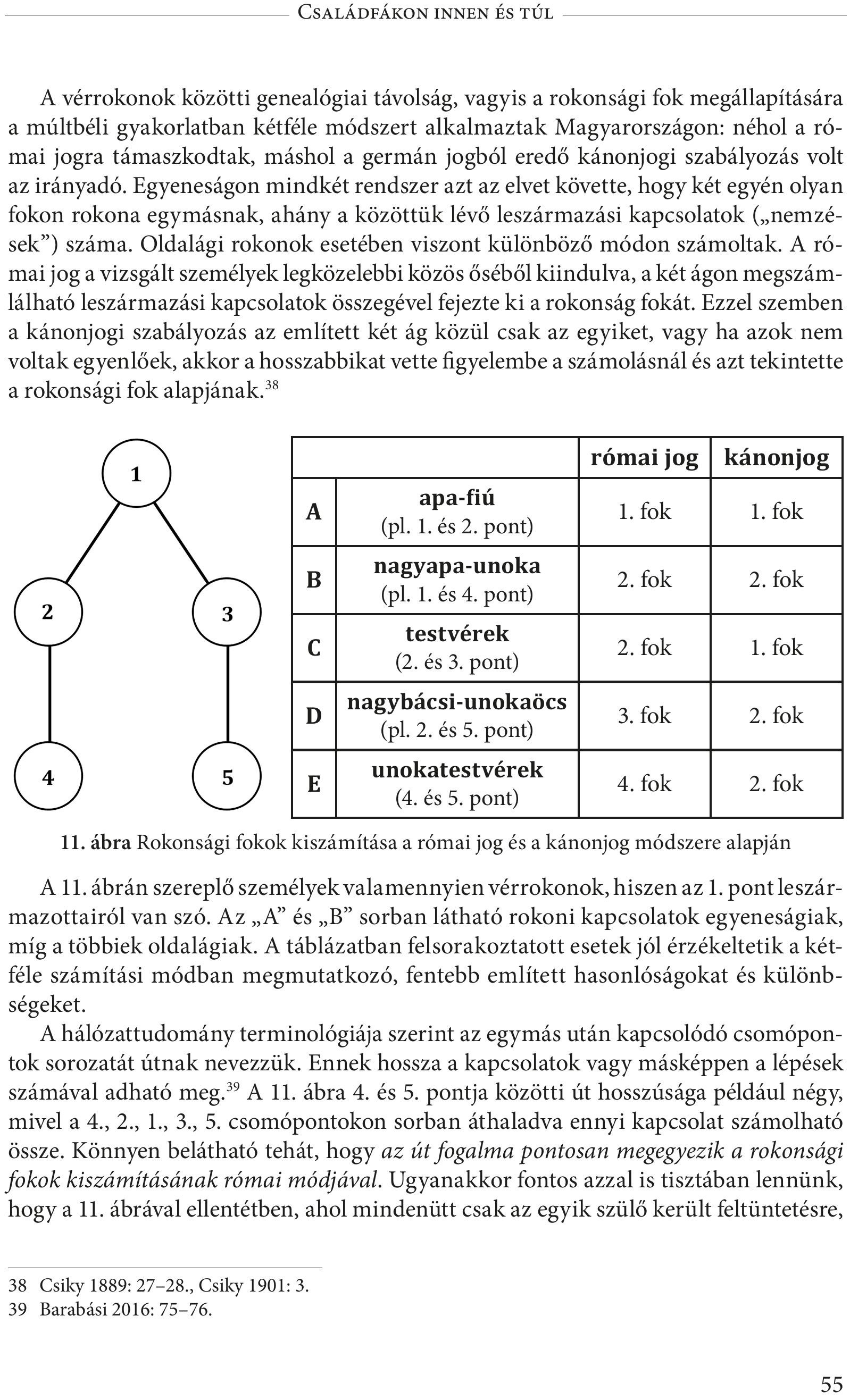
# A táblázat kinyerése egy listába.
tabla <- extract_tables("digitalizacio.pdf",
pages = 56,
encoding = "UTF-8",
output = "data.frame")
# A lista 1. (és jelenleg egyetlen) elemének kinyomtatása.
tibble::as.tibble(tabla[[1]])## # A tibble: 5 × 5
## X X.1 X.2 római.jog kánonjog
## <chr> <chr> <lgl> <chr> <chr>
## 1 A apa-fiú(pl. 1. és 2. pont) NA 1. fok 1. fok
## 2 B nagyapa-unoka(pl. 1. és 4. pont) NA 2. fok 2. fok
## 3 C testvérek(2. és 3. pont) NA 2. fok 1. fok
## 4 D nagybácsi-unokaöcs(pl. 2. és 5. pont) NA 3. fok 2. fok
## 5 E unokatestvérek(4. és 5. pont) NA 4. fok 2. fok
Az első benyomást illetően mindenképpen pozitívumként könyvelhetjük el, hogy emberi beavatkozás nélkül megtalálta a táblázatot az oldalon. Vagyis helyesen ismerte fel, hogy az oldal melyik részével kell foglalkozni. Ha ez véletlenül nem így lenne, akkor a tabulizer::extract_areas() függvénnyel manuálisan is ki lehet jelölni a táblázat helyét. Ennek paraméterei azonosak az előbbivel. A függvény futtatásával egy interaktív felületet kapunk a megadott oldal képével, ahol az egérrel ki tudjuk jelölni a táblázatot.
Magát a táblázat tartalmát tekintve viszont az látható, hogy bár elég jó, de azért nem tökéletes eredményt kaptunk. Az én tapasztalatom az, hogy általában a táblázatok fejlécén csúszik el a dolog. Jelen esetben a nyomtatott táblázat első két oszlopnak összevont, ráadásul üres fejléce van. És ez egy viszonylag egyszerű példa volt. A többszintű, egymásba ágyazott fejlécek képesek alaposabban is kiakasztani a rendszert. Ezek értelemszerűen nem kompatibilisek az adatkeretek felépítésével, ahol minden oszlophoz egyetlen fejléc tartozik. Ezzel a problémával tehát számolni kell.
Sajnos nem minden PDF kétrétegű, vagyis vannak olyan dokumentumok is, amelyek szövegfelismertetés nélküli szkennelt képeket tartalmaznak. R nyelven ugyan nem tudunk valódi kétrétegű PDF-et csinálni, de a belőlük képként kivont oldalakon lévő szövegek felismertetésére lehetőségünk van.
Ezt a feladatot a tesseract::ocr() függvény végzi el nekünk. Ahhoz, hogy a magyar szövegeken is (nagyjából) helyesen működjön, az első futtatás előtt a tesseract::tesseract_download("hun") utasítással telepíteni kell a gépünkre magyar szavak szótárát.
A tesseract::ocr() függvény a következő paraméterekkel rendelkezik:
| Paraméter | Magyarázat |
|---|---|
| image | a bemeneti képek neve (karakterlánc vagy karakter vektor) |
| engine | a szövegfelismertetés nyelve (függvény) |
A munkafolyamat eleje azonos a fentebb már ismertetett eljárással: kivonjuk a PDF dokumentumból a képeket, majd visszaolvassuk azokat egy változóba. Ezek tehát már rendelkezésünkre állnak a kepek vektorban, amelynek minden eleme a digitalizacio.pdf egy-egy oldalának felel meg.
Az összehasonlíthatóság miatt most is a dokumentum 34. oldalának szövegét fogjuk megnézni. De egyébként az image paraméter egyszerre több oldalt is elfogadna bemenetként.
# Az alábbi sort csak az első használat előtt kell futtatni!
tesseract_download("hun")
# A szöveg kinyerése a kepek vektor 34. eleméből.
szoveg <- ocr(image = kepek[34], engine = tesseract("hun"))
# A kinyert szöveg kinyomtatása.
cat(szoveg)## BALLABÁS DÁNIEL
## Családfákon innen és túl.
## Genealógiai kapcsolatok detektálása
## a hálózatok segítségével
## A történelmi problémáknak a hálózattudomány eszközeivel és módszertanával törté-
## nő megközelítése egyelőre nem tartozik a hazai történészek által különösebben pre-
## ferált tevékenységek közé." Noha maga a hálózattudomány (jelentős matematikai és
## szociológiai előzményekre támaszkodva) csak a 21. század elején jelent meg az önálló
## diszciplínák sorában,? a hálózatként leírható jelenségekkel való tudományos igényű
## foglalatoskodás ennél sokkal régebbi keletű. Amikor például Nagy Iván a Magyaror-
## szág családai czímerekkel és nemzékrendi táblákkal címet viselő, 1857 és 1868 között
## 13 kötetben megjelent munkáját közreadta, egészen biztosan nem gondolt arra, hogy
## ő valójában hálózatokkal foglalkozik. Pedig lényegében erről volt szó. Ahogy az első
## kötet bevezető soraiban olvashatjuk: , Nemzetünk történelméhez adni kalauzt, mely
## a szerepelt személyek eredetével, családi összeköttetéseivel ismertet meg, -— főczélja
## e gyüjteménynek." Tudniillik a hálózat egy olyan rendszer, amely csomópontokból
## és a köztük lévő kapcsolatokból (linkekből) áll." Nagy Iván idézett munkája esetében
## a csomópontokat a személyek, míg a kapcsolatokat a horizontális és vertikális családi
## összeköttetések jelentik. Ezek alapján a kötetben szereplő családfák tökéletesen leír-
## hatók a hálózattudomány számára értelmezhető módon. Mindez Kempelen Béla és
## Gudenus János József sokat forgatott kézikönyveire, valamint az elmúlt másfél évszá-
## zadban napvilágot látott számtalan egyéb genealógiára is ugyanígy igaz. Azaz a háló-
## zatok jelenléte egyáltalán nem újdonság a történelmi tárgyú munkákban, csak éppen
## nem így nevezték őket. A mai kor történészeire vár a feladat, hogy a hálózatként leírha-
## tó struktúrákat felismerjék, és kutatásaikban (újrajhasznosítsák azokat. Megjegyzendő
## t A tanulmány elkészítését az EFOP-3.6.1-16-2016-00001 , Kutatási kapacitások és szolgáltatások
## komplex fejlesztése az Eszterházy Károly Egyetemen" című pályázat támogatta. Ugyancsak köszönöm
## az NKFIH 112429 , A dualizmus kori magyar országgyűlések tagjainak feltárása és társadalomtörténe-
## ti elemzése" címet viselő pályázatának támogatását.
## 1 Arpkivételek között említhető: Bozsonyi-Horváth-Kmetty 2012, Horváth 2013, Horváth 2017, Markó
## 2018, Nagy 2019, Szántay 2014, Pap 2016, Rab 2017, Tózsa-Rigó 2014. Elméleti megközelítésként:
## Brandt 2003, Kovács 2012.
## 2 Barabási2016: 40.
## 3 Nagy 1857-1868: I. kötet előszó, oldalszám nélkül.
## 4 Barabási2016: 60.
## 33
Ahogy látható, a tördelési különbségektől eltekintve a szövegfelismertetés szinte tökéletes. Hozzá kell persze tenni, hogy a háttérben álló nyelvi szótár a mai magyar nyelvre van felkészítve. Egyáltalán nem biztos tehát, hogy egy régies nyelvezetű szöveget is ilyen szépen felismerne. Bár a tesseract elvileg tanítható, így nem kizárt, hogy ez is megoldható lenne.
Végezetül nincs más dolgunk, mint a dokumentumból kivont vagy felismertetett szöveget kiírni egy TXT fájlba. Ezt a következő utasítással tehetjük meg: base::writeLines(text = szoveg, con = file("szoveg.txt")). Az eredmény a munkakönyvtárunkba, a szoveg.txt fájlba mentődik el.