A bar chart race típusú diagramok az utóbbi években jöttek divatba és terjedtek el széleskörűen. A népszerűségük okáról és a használhatóságukról a vélemények megoszlanak. Egyesek kifejezetten zavarónak és tudományos célokra alkalmatlannak érzik ezeket a mozgó ábrákat. Mások viszont inkább az élményszerűségüket, az érzelmekre gyakorolt hatásukat hangsúlyozzák. Szerintük ezek az előnyök bizonyos esetekben képesek ellensúlyozni a nehezebb olvashatóságból eredő hátrányokat.
Jómagam először az ókígyósi kastély vendégkönyvének feltárásakor készítettem bar chart race típusú ábrát. Ez jelentősen hozzájárult ahhoz, hogy megértsem az egyes látogatói csoportok egymáshoz viszonyított arányában az idő előrehaladtával bekövetkező eltolódásokat. Ezen felbátorodva szeretném most bemutatni, hogy miként lehet egy hasonló diagramot R nyelven elkészíteni.
Az előző blogposztomban megszerzett adatokra alapozva egy olyan ábra előállítása a cél, amely minden egyes olimpiai évben megmutatja, hogy az első újkori olimpia óta felhalmozott érmeik száma alapján melyik az aktuálisan legeredményesebb tíz nemzeti csapat.
Végezetül mindez lehetővé teszi majd, hogy a két említett ábra alapján megfogalmazzam a saját benyomásomat is a bar chart race használhatóságáról.
Az adatok előkészítése
Egy vizualizáció elkészítése nem csupán az ábra összerakásából áll. Ehhez mindenekelőtt szükség van egy megfelelő adatkészletre is. Az adatok beszerzése, megtisztítása és átstrukturálása sokszor a legidőigényesebb feladat az egész munkafolyamat során. Talán mondanom sem kell, hogy az adatok minőségének meghatározó szerepe van az elkészült ábra minőségében is. Szóval mielőtt nekiesünk a bar chart race elkészítésének, érdemes az adatkészletünket alaposan áttanulmányozni.
Az alábbiakban R nyelven (v4.0.3) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
Először is töltsük be a szükséges adatokat. Ehhez nincs más dolgunk, mint az előző posztomban közölt 1. és 3. kódblokk teljes tartalmát egyszerűen bemásolni az új R script elejére. Ezt lefuttatva az adatok a tablaGyujto nevű adatkeretbe kerülnek.
# Ide kell bemásolni az előző posztból az 1. és 3. kódblokk tartalmát.
# Az adatkeret felépítésének megtekintése.
str(tibble::as.tibble(tablaGyujto))## tibble [1,344 × 7] (S3: tbl_df/tbl/data.frame)
## $ orszag : chr [1:1344] "United States" "Greece" "Germany" "France" ...
## $ arany : int [1:1344] 11 10 6 5 2 2 2 2 1 1 ...
## $ ezust : int [1:1344] 7 18 5 4 3 1 1 0 2 2 ...
## $ bronz : int [1:1344] 2 19 2 2 2 3 2 0 3 0 ...
## $ osszesen: int [1:1344] 20 47 13 11 7 6 5 2 6 3 ...
## $ ev : num [1:1344] 1896 1896 1896 1896 1896 ...
## $ helyszin: chr [1:1344] "Athens, Greece" "Athens, Greece" "Athens, Greece" "Athens, Greece" ...
A Wikipédián szereplő, onnan learatott táblázatok azokat a nemzeti csapatokat tartalmazzák, amelyek az adott olimpián legalább egy érmet szereztek. A táblázatok minden sora egy-egy csapatot reprezentál. Azok a csapatok, amelyek több olimpián is eredményesek voltak, értelemszerűen több táblázatban is előfordulnak a Wikipédián, illetve végül a tablaGyujto adatkeretben több sor vonatkozik rájuk. Ha valamely nemzeti csapat, mint például Franciaországé, az összes olimpián sikeresen szerepelt, akkor 29 sora van az adatkeretben. Magyarország csapata viszont nem vett részt az 1920-as és az 1984-es olimpián, de egyébként mindig éremszerző volt, így az adatkeretben 27 alkalommal jelenik meg.
A betöltött adatkeretnek összesen 1344 sora és 7 oszlopa van. Az utóbbiak az ország elnevezését, a megszerzett arany, ezüst és bronz érmek számát, a megszerzett érmek összes számát, valamint az adott olimpia évét és helyszínét tartalmazzák.
A tervezett bar chart race elkészítéséhez minden olimpiai évre és ezen belül minden nemzeti csapatra vonatkozóan ki kell számítani, hogy az újkori olimpiai játékok elindulása óta összesen mennyi érmet szereztek. A kumulált összegek alapján mind a 29 időmetszetben csökkenő sorba rendezzük a csapatokat és az első tízet megjelenítjük az ábrán. A cél tehát ez.
A helyzet azonban ennél egy kicsit bonyolultabb. Vannak ugyanis olyan országok, amelyek összességében nagyon sikeresek az olimpiákon, de egy-egy alkalommal távol maradtak, vagy éppen nem szereztek érmet. Mivel a kérdéses időmetszetekben hiányoznak a táblázatból, ezért a kumulált összegekben sem fognak megjelenni. Magyarország például, a szocialista blokk csaknem minden országával együtt, kihagyta az 1984-es Los Angeles-i olimpiát, noha egyébként a maga 340 érmével a 7. helyen állt ekkor a nemzeti csapatok összesített versenyében. Ezt a problémát, amely természetesen nem csak Magyarországot érintheti, orvosolni kell.
Az alábbiakban létrehozok egy olyan táblázatot, amelyben a legalább egy olimpiai éremmel rendelkező országok az összes lehetséges időmetszetben, azaz 29 alkalommal fel vannak sorolva. Ezt követően a dplyr csomag left_join() függvényével rászűröm erre az eredeti táblázatunk adatait, az üres helyeket pedig feltöltöm 0-val. Az elnevezés továbbra is tablaGyujto marad. Végezetül a helyszín oszlopot eltávolítom, mert erre most nem lesz szükségünk.
# A szükséges csomag betöltése. A legelső használat előtt
# az install.packages("dplyr") utasítással telepíteni kell ezt.
library(dplyr)
# Az új táblázat létrehozása és feltöltése.
tablaGyujto <- data.frame("orszag" = rep(sort(unique(tablaGyujto$orszag)), each = 29),
"ev" = rep(setdiff(seq(1896, 2020, 4), c(1916, 1940, 1944)), length(unique(tablaGyujto$orszag)))) %>%
left_join(tablaGyujto, by = c("orszag", "ev"))
tablaGyujto[is.na(tablaGyujto)] <- 0
# A helyszín oszlop eltávolítása.
tablaGyujto$helyszin <- NULL
# A Magyarországra vonatkozó adatok kilistázása.
tibble::as.tibble(tablaGyujto[tablaGyujto$orszag == "Hungary",]) %>% print(n = Inf)## # A tibble: 29 × 6
## orszag ev arany ezust bronz osszesen
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Hungary 1896 2 1 3 6
## 2 Hungary 1900 1 2 2 5
## 3 Hungary 1904 2 1 1 4
## 4 Hungary 1908 3 4 2 9
## 5 Hungary 1912 3 2 3 8
## 6 Hungary 1920 0 0 0 0
## 7 Hungary 1924 2 3 4 9
## 8 Hungary 1928 4 5 0 9
## 9 Hungary 1932 6 4 5 15
## 10 Hungary 1936 10 1 5 16
## 11 Hungary 1948 10 5 12 27
## 12 Hungary 1952 16 10 16 42
## 13 Hungary 1956 9 10 7 26
## 14 Hungary 1960 6 8 7 21
## 15 Hungary 1964 10 7 5 22
## 16 Hungary 1968 10 10 12 32
## 17 Hungary 1972 6 13 16 35
## 18 Hungary 1976 4 5 13 22
## 19 Hungary 1980 7 10 15 32
## 20 Hungary 1984 0 0 0 0
## 21 Hungary 1988 11 6 6 23
## 22 Hungary 1992 11 12 7 30
## 23 Hungary 1996 7 4 10 21
## 24 Hungary 2000 8 6 3 17
## 25 Hungary 2004 8 6 3 17
## 26 Hungary 2008 3 5 2 10
## 27 Hungary 2012 8 4 6 18
## 28 Hungary 2016 8 3 4 15
## 29 Hungary 2020 6 7 7 20
A fentiekben látható tehát, hogy a példaként felhozott Magyarországnak immáron külön sora van az 1920-as és az 1984-es olimpián is, amelyekben az érmek számánál 0 szerepel. Most már nincsen akadálya a kumulált összegek kiszámításának.
Itt ugyancsak a dplyr csomag képességeit fogom elsősorban kihasználni:
Az
arrange()függvény egy adatkeret sorainak átrendezésére szolgál.A
group_by()függvény csoportokat képez a paraméterként megadott oszlop adataiból, míg azungroup()függvénnyel eltávolíthatjuk ezeket.A
mutate()függvénnyel műveleteket hajthatunk végre a csoportosított adatokon.A
filter()függvény az adatkeret sorainak leszűrésére szolgál.
Az alábbiakban először létrehozom a kumulált adatokat, majd ezeket alapul véve leszűröm minden olimpiai év 10-10 legtöbb éremmel rendelkező nemzeti csapatát. A továbbiakban a tablaGyujto változóban már csak ez a 290 (= 29*10) sor marad.
Hogy lássuk, miről van szó, ismét leszűröm Magyarországot. A táblázatban azokban az években jelenik meg, amikor az olimpiai érmek halmozott száma alapján benne voltunk a top 10-ben.
# A kumulált értékek előállítása
tablaGyujto <- tablaGyujto %>%
arrange(orszag, ev) %>%
group_by(orszag) %>%
mutate(arany = cumsum(arany)) %>%
mutate(ezust = cumsum(ezust)) %>%
mutate(bronz = cumsum(bronz)) %>%
mutate(osszesen = cumsum(osszesen))
# Az olimpiai évek 10-10 legtöbb éremmel rendelkező csapatának leszűrése.
tablaGyujto <- tablaGyujto %>%
arrange(ev, -osszesen) %>%
group_by(ev) %>%
mutate(sorrend = row_number()) %>%
filter(sorrend <= 10)
# A csoportosítás eltávolítása.
tablaGyujto <- ungroup(tablaGyujto)
# Magyarország jelenléte a top 10-ben.
tibble::as.tibble(tablaGyujto[tablaGyujto$orszag == "Hungary",]) %>% print(n = Inf)## # A tibble: 23 × 7
## orszag ev arany ezust bronz osszesen sorrend
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 Hungary 1896 2 1 3 6 7
## 2 Hungary 1904 5 4 6 15 8
## 3 Hungary 1908 8 8 8 24 10
## 4 Hungary 1912 11 10 11 32 8
## 5 Hungary 1948 43 28 37 108 8
## 6 Hungary 1952 59 38 53 150 8
## 7 Hungary 1956 68 48 60 176 8
## 8 Hungary 1960 74 56 67 197 9
## 9 Hungary 1964 84 63 72 219 9
## 10 Hungary 1968 94 73 84 251 7
## 11 Hungary 1972 100 86 100 286 7
## 12 Hungary 1976 104 91 113 308 7
## 13 Hungary 1980 111 101 128 340 6
## 14 Hungary 1984 111 101 128 340 7
## 15 Hungary 1988 122 107 134 363 8
## 16 Hungary 1992 133 119 141 393 8
## 17 Hungary 1996 140 123 151 414 7
## 18 Hungary 2000 148 129 154 431 8
## 19 Hungary 2004 156 135 157 448 8
## 20 Hungary 2008 159 140 159 458 8
## 21 Hungary 2012 167 144 165 476 9
## 22 Hungary 2016 175 147 169 491 10
## 23 Hungary 2020 181 154 176 511 9
Ezen a ponton akár el is kezdhetnénk az ábra előállítását. Ezt megelőzően viszont még magyarítani akarom a csapatok nevét, hiszen az adatok az angol nyelvű Wikipédiáról származnak. Szerencsére nincs szükségünk arra, hogy egyenként átírjuk az országneveket, mert a countrycode csomag (többnyire) megteszi ezt helyettünk. Manuális beavatkozásra mindössze a manapság már nem létező Soviet Union és East Germany, illetve a kezdeti években jelen lévő “Mixed team” nevű csapatoknál van szükség.
Ugyancsak ezt a csomagot veszem igénybe arra a célra, hogy minden csapathoz hozzárendeljek egy egyedi kódot, amit később a zászlók automatizált felvarázsolásához fogok használni. Ez az azonosító bármi lehetne, de történetesen a Nemzetközi Olimpiai Bizottság (International Olympic Committee – IOC) rendelkezik egy ilyen rendszerrel, amelyet (többnyire) ismer a countrycode csomag is. Manuálisan ismét az említett három csapat korrigálására lesz szükség, amelyek IOC kódját a Wikipédián közzétett listából néztem ki. (Az IOC kódrendszere egyébként is alkalmasnak látszik a történelmi célú felhasználásra, mivel az olimpiákon annak idején elindult, de azóta megszűnt országok önálló kóddal rendelkeznek benne.)
Végezetül megtekintjük e műveletek végeredményét.
# A szükséges csomag betöltése. A legelső használat előtt
# az install.packages("countrycode") utasítással telepíteni kell ezt.
library(countrycode)
# Az országnevek magyarítása.
tablaGyujto$orszagMagyarul <- countryname(tablaGyujto$orszag, "cldr.name.hu")
tablaGyujto[tablaGyujto$orszag == "Soviet Union", "orszagMagyarul"] <- "Szovjetunió"
tablaGyujto[tablaGyujto$orszag == "East Germany", "orszagMagyarul"] <- "Német Demokratikus Köztársaság"
tablaGyujto[tablaGyujto$orszag == "Mixed team", "orszagMagyarul"] <- "Nemzetközi Csapat"
# Az IOC kódok rögzítése.
tablaGyujto$IOC <- countrycode(tablaGyujto$orszag, "country.name", "ioc")
tablaGyujto[tablaGyujto$orszag == "Soviet Union", "IOC"] <- "URS"
tablaGyujto[tablaGyujto$orszag == "East Germany", "IOC"] <- "GDR"
tablaGyujto[tablaGyujto$orszag == "Mixed team", "IOC"] <- "ZZX"
# A végeredmény megtekintése.
tibble::as.tibble(unique.data.frame(tablaGyujto[,c("orszag", "orszagMagyarul", "IOC")])) %>% print(n = Inf)## # A tibble: 21 × 3
## orszag orszagMagyarul IOC
## <chr> <chr> <chr>
## 1 Greece Görögország GRE
## 2 United States Egyesült Államok USA
## 3 Germany Németország GER
## 4 France Franciaország FRA
## 5 Great Britain Egyesült Királyság GBR
## 6 Denmark Dánia DEN
## 7 Hungary Magyarország HUN
## 8 Austria Ausztria AUT
## 9 Switzerland Svájc SUI
## 10 Australia Ausztrália AUS
## 11 Mixed team Nemzetközi Csapat ZZX
## 12 Belgium Belgium BEL
## 13 Sweden Svédország SWE
## 14 Canada Kanada CAN
## 15 Finland Finnország FIN
## 16 Norway Norvégia NOR
## 17 Italy Olaszország ITA
## 18 Soviet Union Szovjetunió URS
## 19 Japan Japán JPN
## 20 East Germany Német Demokratikus Köztársaság GDR
## 21 China Kína CHN
Ezzel meg is vagyunk az adatok előkészítésével. Itt szeretném megjegyezni, hogy a csapatok nevének magyarítását leszámítva abban a formában hagytam mindent, ahogy az angol nyelvű Wikipédián találtam.
Bár bizonyos esetekben indokoltnak látszana egyes csapatok összevonása, például Kelet- és Nyugat-Németországé, ami nyilvánvalóan befolyásolná a Németország néven szereplő csapat pozícióját, többnyire azonban olyan dilemmákat vetne fel ez az eljárás, amelyeket nem lehet egyértelműen eldönteni. Így némi gondolkodás után úgy döntöttem, hogy nem változtatok semmin. Ha valaki ambíciót érez magában a csapatok összevonására, akkor a lehetőség adott rá.
# Az adatkeret felépítésének megtekintése.
str(tibble::as.tibble(tablaGyujto))## tibble [290 × 9] (S3: tbl_df/tbl/data.frame)
## $ orszag : chr [1:290] "Greece" "United States" "Germany" "France" ...
## $ ev : num [1:290] 1896 1896 1896 1896 1896 ...
## $ arany : num [1:290] 10 11 6 5 2 1 2 2 1 2 ...
## $ ezust : num [1:290] 18 7 5 4 3 2 1 1 2 0 ...
## $ bronz : num [1:290] 19 2 2 2 2 3 3 2 0 0 ...
## $ osszesen : num [1:290] 47 20 13 11 7 6 6 5 3 2 ...
## $ sorrend : int [1:290] 1 2 3 4 5 6 7 8 9 10 ...
## $ orszagMagyarul: chr [1:290] "Görögország" "Egyesült Államok" "Németország" "Franciaország" ...
## $ IOC : chr [1:290] "GRE" "USA" "GER" "FRA" ...
Végeredményül tehát egy 290 sort és 9 oszlopot tartalmazó táblázatot kaptunk. Ennek azonban nemcsak a tartalma, hanem a szerkezete is figyelmet érdemel.
Az adatokat számos módon elrendezhetjük egy táblázatban. Az Excelben a "széles" formátumú, sok oszlopból álló adatkészletekhez vagyunk hozzászokva. A ggplot2 csomaggal és annak kiterjesztéseivel készülő vizualizációk viszont inkább a "hosszú" formátumú adatokat szeretik.
A kettő közötti különbséget nem könnyű megfogalmazni. Egy idő után ráérez erre az ember, de addig is érdemes a belinkelt anyagot áttanulmányozni, mert nem fogad el bármit a ggplot2 vizualizációs rendszer.
A vizualizáció előállítása
A továbbiakban a ggplot2, a gganimate, a ggimage és az extrafont csomagokat fogom használni. Töltsük be ezeket!
Egyúttal hozzunk létre egy munkakönyvtárat a számítógépünkön. Töltsük le ide, majd csomagoljuk ki a zaszlok.zip fájlt. (Ezt automatikusan megteszi az alábbi kód.) Ebben annak a 21 nemzeti csapatnak a zászlaja található, amelyek a top 10-es listában előfordulnak. A képek a Wikipédiáról származnak, vagyis a CC-BY-SA-3.0 licenc alapján szabadon használhatók. A zászlókat egységes méretűre vágtam és a fentebb már említett IOC kódoknak megfelelően neveztem el őket.
# A szükséges csomagok betöltése.
# A legelső használat előtt az install.packages("...") utasítással telepíteni
# kell ezeket. A ... helyére az adott csomag neve írandó.
library(ggplot2)
library(gganimate)
library(ggimage)
library(extrafont)
# font_import()
# Csak az extrafont első használatakor szükséges!
# Ide a saját munkakönyvtárunk elérését kell beírni!
setwd("C:/Munkakönyvtár")
# A zaszlok.zip fájl letöltése a munkakönyvtárba.
download.file("https://aprogramozotortenesz.hu/bar-chart-race-keszitese-r-nyelven/zaszlok.zip", "zaszlok.zip")
# A zaszlok.zip fájl kicsomagolása.
unzip("zaszlok.zip")
A ggplot2 csomaggal készülő ábrák esetében a munkafolyamat abból áll, hogy egy kezdetben üres derékszögű koordináta-rendszer adott pontjaira különböző alakzatokat, szövegeket, képeket helyezünk el. Lényegében úgy dolgozunk, mintha átlátszó fóliákra rajzolnánk vagy írnánk, majd ezeket a fóliákat adott sorrendben egymásra rétegeznénk. A fentebb lévő rétegek rajzolatai kitakarhatják az alattuk lévő rétegek egyes részleteit, a diagram végső megjelenése pedig a rétegek összességéből bontakozik ki.
Az egyes rétegek rajzolatának elhelyezkedését, méretét és kinézetét részint a háttérben álló táblázatban szereplő adatok határozzák meg, részint direktben adjuk meg.
A továbbiakban a koordináta-rendszer adott pontjaiban elhelyezzük a szükséges alakzatokat, szövegeket, képeket, majd az egész ábrát a függőleges tengelye mentén tükrözzük és az óramutató járásának megfelelően elforgatjuk 90 fokkal. A bar chart race típusú ábrákon ugyanis vízszintesen szoktak megjelenni az “oszlopok”. Tehát az adatokat a normál tájolásnak megfelelően kell megadnunk, de a végeredményt már egy elfordított ábrát látjuk majd.
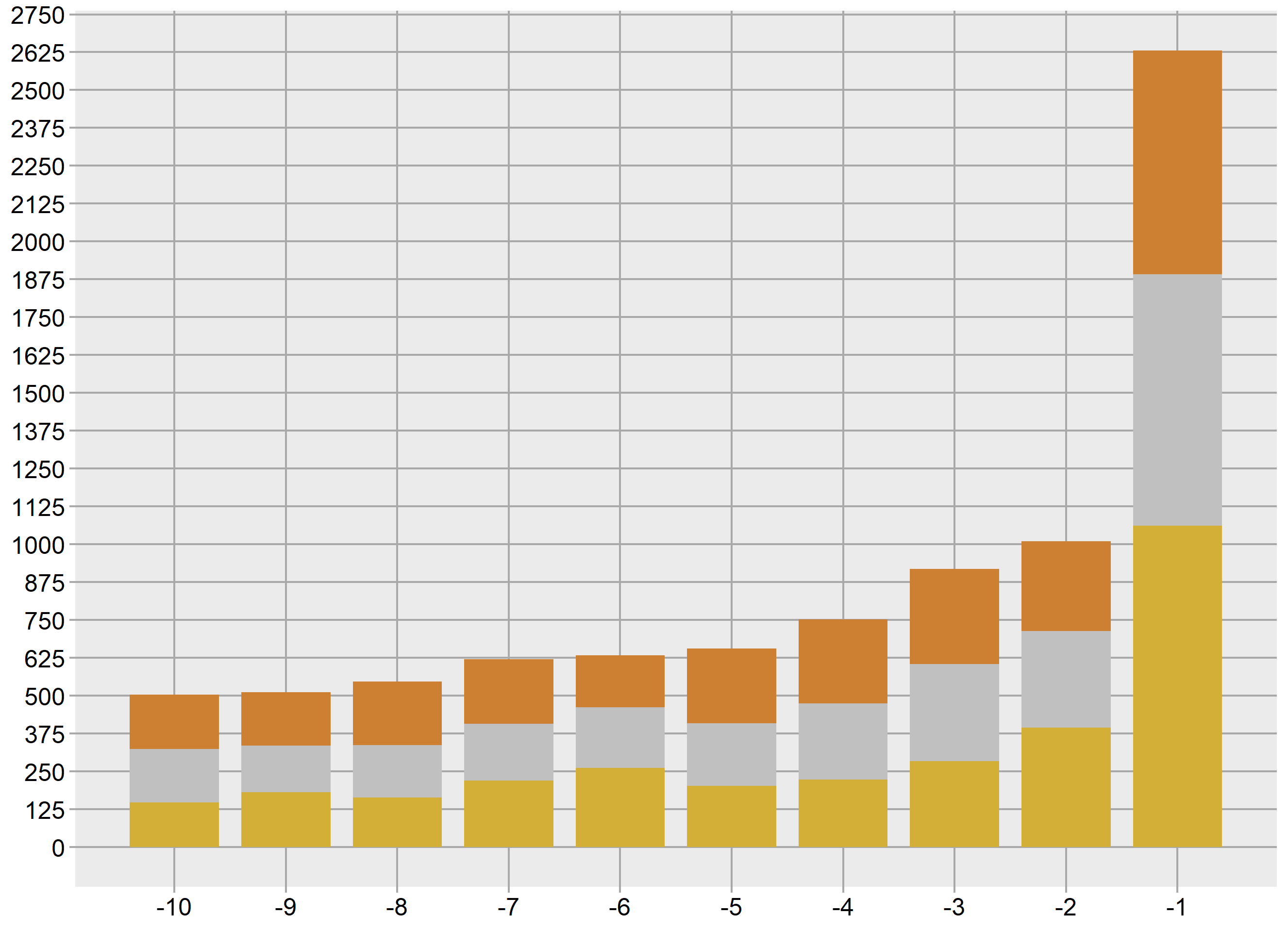
Az ábra eredeti elrendezése egy adott időmetszetben
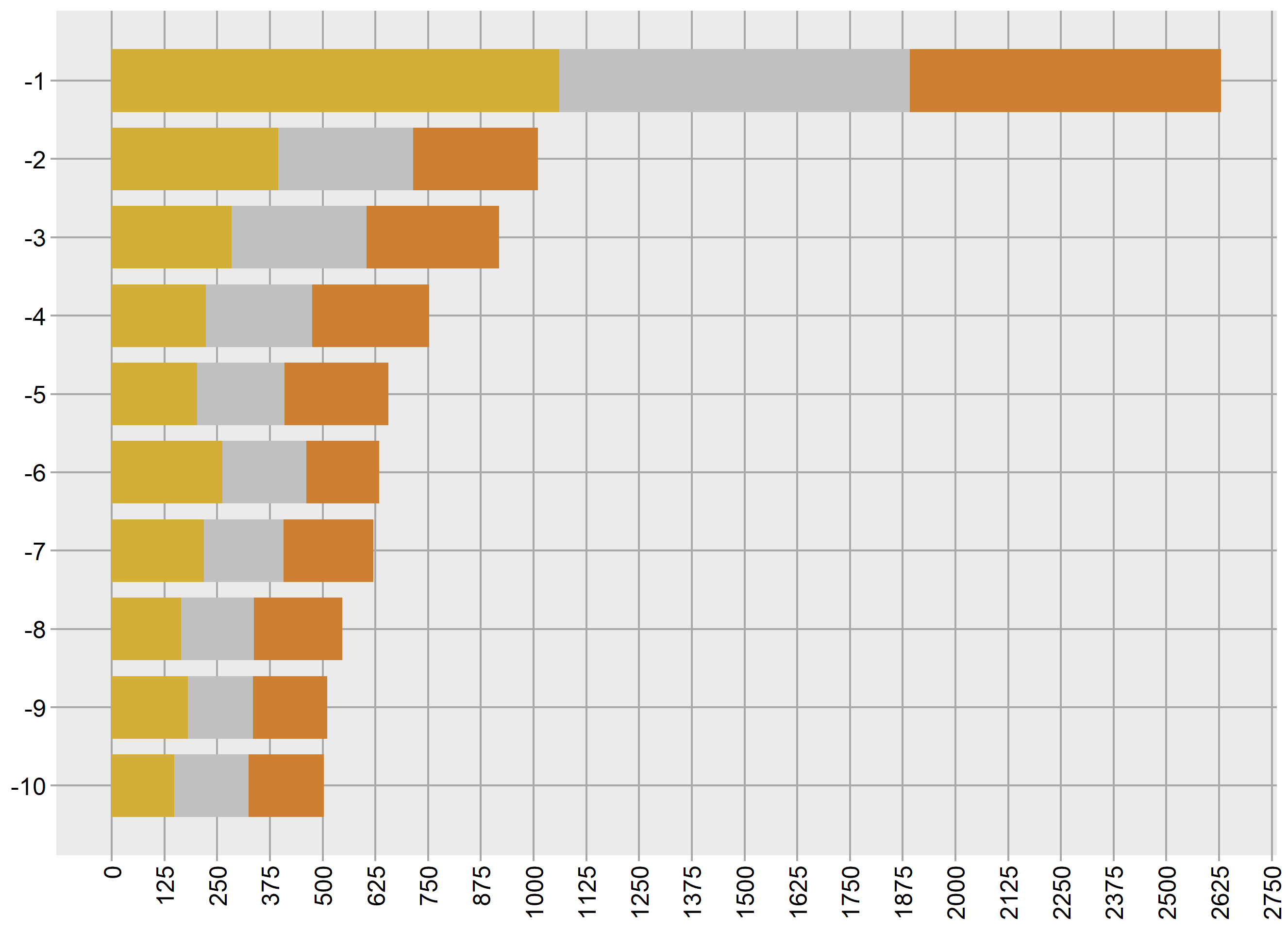
A fenti ábra elfordított elrendezése
Az elkészítendő ábrán a sávok egy-egy konkrét nemzeti csapatot reprezentálnak. Méretük az adott időpontig általuk megszerzett összes arany, ezüst és bronz érmeknek megfelelő nagyságú. Jelenlétüket és sorrendjüket az adott év top 10-es pozíciója határozza meg.
A ggplot2 – folytonos skála használata esetén – alapból növekvő sorrendben halad, vagyis az eredeti ábrán a bal oldali, az elforgatott ábrán pedig az alsó sáv lenne a legeredményesebb csapat, mivel ehhez tartozik a legkisebb sorszám. Mi viszont a legfelső sávban szeretnénk látni a legeredményesebb csapatot, amit úgy tudunk elérni, hogy mínusz értékekkel dolgozunk. (Ha megszorozzuk mínusz 1-gyel a pozíciókat, akkor értelemszerűen megfordul a sorrendjük.)
Az ábrát kisebb kódrészletekből fogom összerakni. Az egyes darabokat a plot nevű változóba mentem el és plusz jellel kapcsolom egymáshoz.
Elsőként a tablaGyujto változóban eltárolt adatkészletet adom meg. Ez a továbbiakban átöröklődik a diagram minden egyes rétegére, azok tehát ebből táplálkoznak.
# Az adatkészlet megadása.
plot <- ggplot(data = tablaGyujto)
A ggplot2-ben az egyes alakzatokat, szövegeket és képeket önálló rétegekként tudjuk hozzáadni az ábránkhoz. Ezek mindegyikéhez egy-egy speciális, kifejezetten az adott vizualizációs feladat megvalósítására szolgáló függvény tartozik. Elnevezésük általában – bár nem kizárólagosan – a geom_név() sémát követi. A The R Graph Gallery oldalon egy rendszerezett, reprodukálható kódokkal kiegészített válogatást találunk belőlük.
Az érmek sávjainak kialakítása
A bar chart race nevéből talán az következne, hogy a rendelkezésre álló lehetőségek közül a geom_bar() elnevezésű réteget kell választanunk. A klasszikus oszlopdiagramok rajzolására kitalált réteg azonban nem méretezhető olyan rugalmasan, mint ahogy nekünk arra szükségünk lenne. Ezért a geom_tile() nevű réteget fogom bevetni erre a célra, amellyel négyszögletű “csempéket” rajzolhatunk a koordináta-rendszerünkre. A réteg általunk használt tulajdonságai az alábbiak.
| Tulajdonság | Magyarázat |
|---|---|
| x | a csempe középpontjának x koordinátája (numerikus érték) |
| y | a csempe középpontjának y koordinátája (numerikus érték) |
| width | a csempe szélessége (numerikus érték) |
| height | a csempe magassága (numerikus érték) |
| fill | a csempe kitöltésének színe (karakterlánc) |
Ha az adott réteg használatakor a háttérben álló adatkeret valamely oszlopára, vagyis az abban szereplő adatokra hivatkozunk, akkor azt a réteg mapping nevű paramétereként, az aes() függvénybe csomagolva kell megadni, például: geom_név(mapping = aes(x = oszlop1, y = oszlop2)). Ekkor az adatkeret sorainak megfelelő számú elem jelenik meg az ábrán.
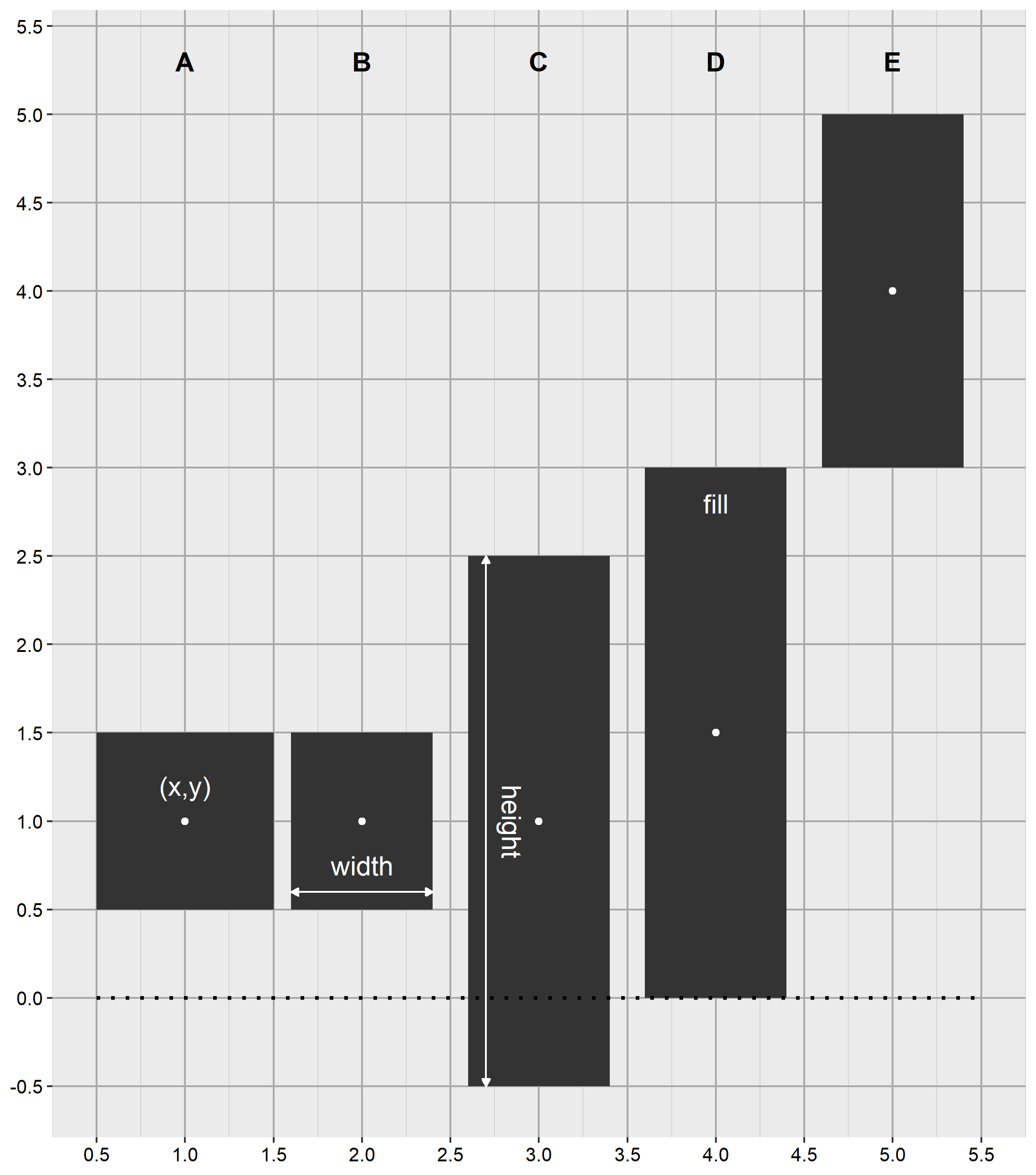
A geom_tile() réteg tulajdonságai
Az x és az y kötelező tulajdonság, a csempe középpontjának koordinátái. Ha semmi mást nem adunk meg, akkor 1 egység széles és 1 egység magas négyszöget kapunk. (“A” ábra) (Nem feltétlenül négyzetet! A csempe tényleges alakja attól függ, hogy végül milyen oldalaránnyal nyomtatjuk ki az ábrát.)
A mi esetünkben egyéb tulajdonságok megadására is szükség van. Amennyiben a szélességnél megmaradnánk az 1 egységnél, akkor a sávok egymáshoz érnének, amit nem akarunk. Ezért a width tulajdonság értékét némileg csökkenteni kell. (“B” ábra)
A height tulajdonság értéke, vagyis az oszlop magassága az arany, az ezüst és a bronz érmek számához igazodik. Ezek viszont csak akkor fognak helyesen megjelenni, ha a csempe középpontját megfelelően adjuk meg. Önmagában a magasság egyáltalán nem garantálja azt, hogy adott csempe alja az x tengelyhez vagy bármely más csempéhez illeszkedni fog. (“C” ábra) Ehhez a csempe középpontjának y koordinátáját a következőképpen kell kiszámolni: y = csatlakozási pont y koordinátája + magasság / 2. (“D” és “E” ábra)
Az ábránkon három különböző geom_tile() réteget szerepel, a fenti elveknek megfelelően előállítva.
plot <- plot +
geom_tile(mapping = aes(x = -sorrend,
y = arany / 2,
height = arany),
width = 0.8,
fill = "#d4af37") +
geom_tile(mapping = aes(x = -sorrend,
y = arany + ezust / 2,
height = ezust),
width = 0.8,
fill = "#c0c0c0") +
geom_tile(mapping = aes(x = -sorrend,
y = arany + ezust + bronz / 2,
height = bronz),
width = 0.8,
fill = "#cd7f32")A csapatok nevének és az érmek számának elhelyezése
Ezt követően azokat a feliratokat helyezem el az ábrán, amelyek a csapatok nevét és az érmek összes számát mutatják meg. A geom_text() réteg általunk használt tulajdonságai az alábbiak.
| Tulajdonság | Magyarázat |
|---|---|
| x | a szöveg középpontjának x koordinátája (numerikus érték) |
| y | a szöveg középpontjának y koordinátája (numerikus érték) |
| label | maga a szöveg (karakterlánc) |
| hjust | a szöveg vízszintes igazítása (numerikus érték) |
| size | a szöveg mérete (numerikus érték) |
| family | a szöveg betűtípusa (karakterlánc) |
A szövegek igazításánál általában 0 és 1 közötti értékeket használunk, ahol a két szélsőség a balra és a jobbra való igazítást jelenti. Az alapértelmezés szerinti 0.5 érték esetén a szöveg közepe pontosan az (x,y) koordinátára esik. Ugyanakkor megadhatunk az intervallumból kilógó értéket is, amivel nagyobb mértékű eltolást lehet elérni.
A family tulajdonságnak akkor van hatása, ha az extrafont csomagot betöltöttük. Én itt a Bahnschrift betűtípust adtam meg. Értelemszerűen ez csak akkor fog helyesen működni az olvasó gépén, ha nála is telepítve van ez. Egyébként javítani kell a kódot. A rendelkezésre álló betűtípusokat a fonts() függvénnyel tudjuk kilistázni.
plot <- plot +
geom_text(mapping = aes(label = osszesen,
y = osszesen,
x = -sorrend),
hjust = -0.2,
size = 7,
family = "Bahnschrift") +
geom_text(mapping = aes(label = toupper(orszagMagyarul),
x = -sorrend),
y = -230,
hjust = 1,
size = 7,
family = "Bahnschrift")A zászlók felhelyezése
A ggimage csomag részét képező geom_image() réteg arra szolgál, hogy raszteres képeket helyezzünk el a koordináta-rendszer adott pontjaiban.
A zászlók felhelyezéséhez első megközelítésre kézenfekvőbbnek látszana a ggimage csomag részét képező geom_flag() réteg, vagy akár a ggflags csomag használata. Ezekkel azonban az a probléma, hogy csak a jelenleg létező országok zászlóit ismerik. Azaz a Szovjetunió, Kelet-Németország és a Nemzetközi Csapat lobogóját nem tartalmazzák. Éppen ezért saját megoldást kellett kitalálnom ezek megjelenítésére.
Ehhez a fentebb említettek szerint lementettem a Wikipédiáról és egységes méretűre vágtam az érintett csapatok zászlóit. Ezeket korábban letöltöttük, így rendelkezésre állnak a munkakönyvtárunkban.
# A munkakönyvtár tartalmának kilistázása
dir()## [1] "AUS.png" "AUT.png" "BEL.png" "CAN.png" "CHN.png" "DEN.png" "FIN.png"
## [8] "FRA.png" "GBR.png" "GDR.png" "GER.png" "GRE.png" "HUN.png" "ITA.png"
## [15] "JPN.png" "NOR.png" "SUI.png" "SWE.png" "URS.png" "USA.png" "ZZX.png"
A cél az, hogy a lementett zászlók automatikusan csatlakozzanak az adatkeretünk megfelelő soraihoz. Ezt úgy értem el, hogy egyrészt legeneráltam és felvettem az adatkeretbe az egyes csapatok IOC kódját, másrészt ezeknek megfelelően neveztem el a zászlókat is. Vagyis a táblázat IOC nevű oszlopának tartalmához a paste0() függvénnyel a “.png” karakterláncot hozzáfűzve megkapjuk a fájlok elérési útvonalát. A Magyarországot reprezentáló sorok és az IOC oszlop metszéspontjában például a “HUN” karakterlánc szerepel, ezért a magyar zászló a “HUN.png” néven került elmentésre.
A geom_image() réteg általunk használt tulajdonságai a következők.
| Tulajdonság | Magyarázat |
|---|---|
| x | a kép középpontjának x koordinátája (numerikus érték) |
| y | a kép középpontjának y koordinátája (numerikus érték) |
| image | a fájl elérési útvonala (karakterlánc) |
| by | a méretezés viszonyítási alapja (karakterlánc) |
| size | a kép mérete (numerikus érték) |
A ggimage csomag dokumentációja sajnos eléggé szűkszavú, ezért a by és a size tulajdonsággal kapcsolatban csak sejtéseim vannak. Az biztos, hogy az előbbi esetében a “width” és a “height” értékekből lehet választani. Ezzel azt adhatjuk meg, hogy az ábra szélességét vagy a magasságát akarjuk szabályozni a size tulajdonsággal. Az utóbbi mértékegységéről azonban sajnos nincsen információm. Ilyenkor a kísérletezés döntheti el a helyes méretezést.
plot <- plot +
geom_image(mapping = aes(image = paste0(IOC,".png"),
x = -sorrend),
y = -120,
by = "height",
size = 0.03)Az ábra egyéb elemei
A munka lényegi részével meg is vagyunk. Az ördög persze a részletekben rejtőzik, ezért az alábbiakban még finomítunk az ábrán és elhelyezünk rajta néhány feliratot.
plot <- plot +
# A tengelyek felcserélése és testre szabása.
# Ettől kezdve az elfordított ábra a viszonyítási alap az x és y
# tengely meghatározásakor!
coord_flip(clip = "off") +
scale_y_continuous(expand = expansion(add = 0),
name = "Az összes érmek száma és belső megoszlása [arany|ezüst|bronz]") +
scale_x_continuous(expand = expansion(add = 0)) +
# Az ábra egyéb alkotórészeinek testreszabása.
theme(axis.text = element_blank(),
axis.title.y = element_blank(),
axis.title.x = element_text(size = 20, family = "Bahnschrift", margin = margin(t = 10, b = 20)),
axis.ticks = element_blank(),
panel.background = element_blank(),
panel.grid = element_blank(),
plot.margin = margin(1,2,1,15,"cm"),
plot.title = element_text(face = "bold", size = 40, family = "Bahnschrift", hjust = 1),
plot.subtitle = element_text(size = 55, family = "Bahnschrift", margin = margin(t = 5, b = 20), hjust = 1),
plot.caption = element_text(size = 16, family = "Bahnschrift")) +
# Az ábra feliratozása.
labs(title = "Minden idők legeredményesebb csapatai a nyári olimpiákon\naz adott évből visszatekintve:*",
subtitle = "{closest_state}",
caption = "*Az adatok forrása: Wikipédia\nhttps://aprogramozotortenesz.hu/olimpiai-eremtablazatok-learatasa-a-wikipediarol/")
Ha a plot nevű változót most “kinyomtatjuk” a képernyőre, akkor az alábbi ábrát kapjuk.
plot
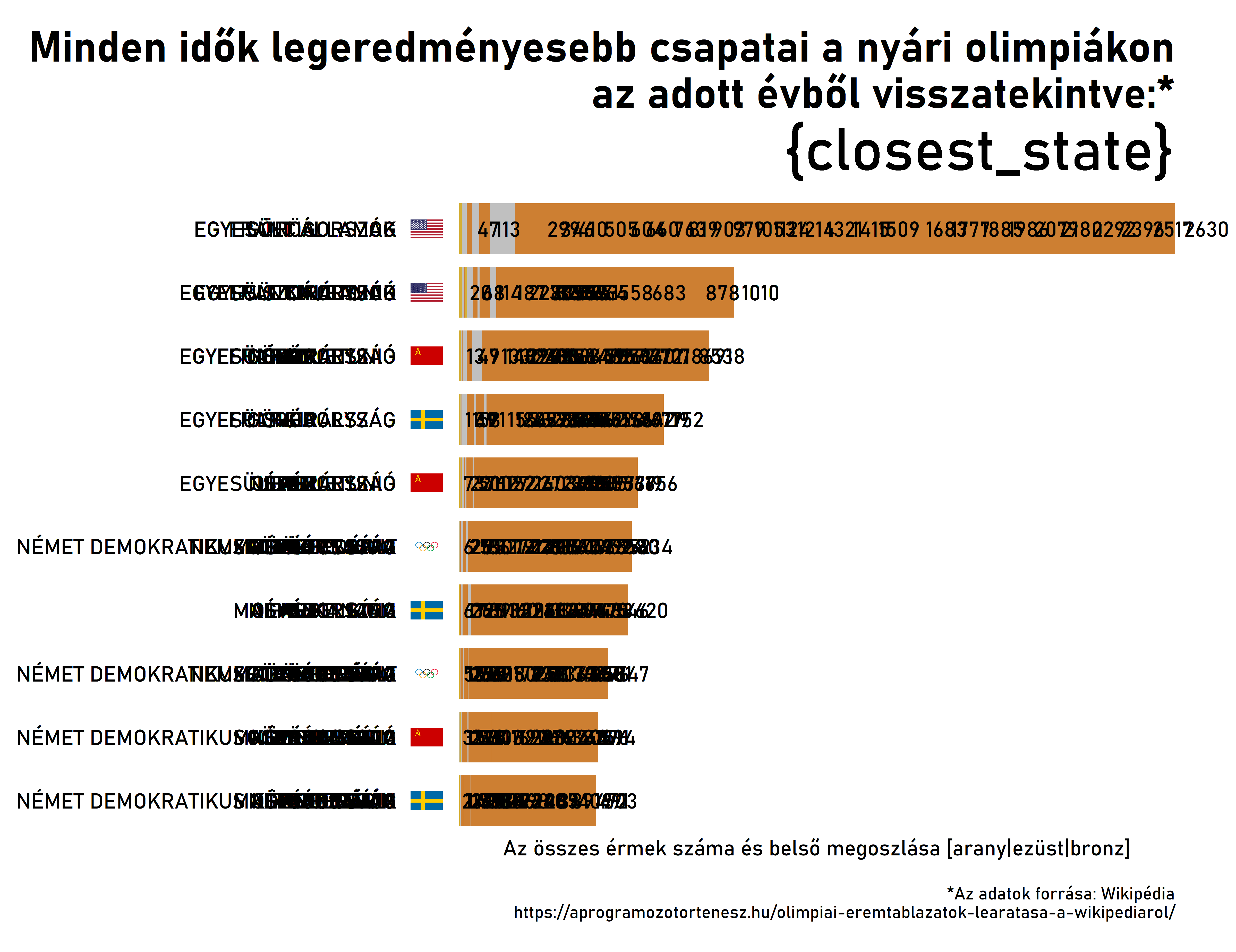
A plot nevű változó tartalma
A fenti ábra első ránézésre zavarosnak és hibásnak tűnik, de technikai szempontból valójában nincsen vele probléma. Jobban belegondolva ugyanis a helyzet az, hogy bemenetként egy olyan adatkészletet adtunk meg, amelyben egyszerre 29 időmetszet szerepel. Ez a gyakorlatban azt jelenti, hogy a koordináta-rendszer egy-egy pontjára – vagy egymástól némileg elcsúsztatva – 29 különböző adat került felrajzolásra. Ezek értelemszerűen fedhetik egymást. Mindez nem hiba, a ggplot2 így működik.
Az ábra mozgásra bírása
A gganimate csomag lényegében azt csinálja, hogy egy megadott oszlopban lévő azonos adatokból csoportokat képez – esetünkben ezek az olimpiai évek. Majd sorban végigmegy a csoportokon, mindegyikhez leszűri az adatkeret releváns sorait és elkészít az ábrát. Végül pedig az ábrákat bizonyos effektekkel kiegészítve egymáshoz fűzi.
A csoportosítás alapját képező oszlop értékei nemcsak az adatkeret leszűrése miatt lehetnek fontosak a számunkra, hanem magán az ábrán is megjeleníthetjük azokat. Az ábra egyéb elemei bekezdés első kódblokkjának 22. sorában a subtitle = "{closest_state}" utasítás szerepel. Itt a diagram alcímének megadását látjuk, ami alapesetben bármilyen szöveg lehetne. A {closest_state} azonban egy olyan speciális változó, amely minden alkalommal, amikor a táblázat leszűrésre kerül, felveszi az aktuális csoportnak megfelelő értéket. Azaz az olimpiai évet. Ez kerül bele az ábra alcímébe.
A gganimate csomag számos olyan, most nem használt megoldást és effektet tartalmaz, amelyekkel fel lehet dobni egy mozgó diagramot. Ezeknek érdemes utánanézni a csomag dokumentációjában!
# A csoportosítás alapjául szolgáló oszlop és az egyes ábrák közötti átmenet
# jellegének megadása.
plot <- plot +
transition_states(ev) +
ease_aes("linear")
# Az animáció előállítása.
animate(plot, end_pause = 30, width = 1200, height = 1200, duration = 20)
# Az animáció mentése.
anim_save("olimpiaBarChartRace.gif")

Minden idők legeredményesebb csapatai a nyári olimpiákon az adott évből visszatekintve
Konklúzió
Az alapötlet a bar chart race készítéséhez az ókígyósi Wenckheim-kastély vendégkönyvének feldolgozásából származik. Ott a látogatókat öt kategóriába soroltam, majd az ezen kategóriákba tartozó személyek létszámának időbeli változását, illetve a belső arányuk eltolódását szemléltettem.
Ehhez képest a mostani ábra annyiban mindenképpen más, hogy az ábrázolt kategóriák, vagyis az aktuálisan megjelenített olimpiai csapatok száma ugyan kötött, de a konkrét kategóriák viszont folyamatosan cserélődnek.
A két ábra összehasonlítása alapján az én véleményem az, hogy tudományos célokra inkább az elsőként említett jelenség ábrázolásánál érdemes ezt a fajta vizualizációt használni. Tehát abban az esetben, ha teljesülnek az alábbi feltételek:
viszonylag kevés kategóriánk van,
azok mindegyike folyamatosan jelen van az ábrán,
elsősorban a belső arányeltolódások megmutatása a célunk.
Érzésem szerint a jelenlegi ábrán olyan sok információ szerepel, hogy azokat lehetetlen egyszerre nyomon követni. Bár kinézetre tetszetős és az emberek általában szeretik az ilyen izgő-mozgó dolgokat, de a konkrét eredményeket az adatok gyors váltakozása miatt nem tudjuk leolvasni róla. Le lehetne persze lassítani, de akkor elveszne a mozgásból eredő élmény és statikus diagramok sorát kapnánk.
A technikai kivitelezés fentebb bemutatott módszere azonban ettől független. Ezzel ugyanúgy lehet értelmes és értelmetlen ábrákat is készíteni. A dolog ezen része már az olvasón múlik.