A webaratás (web harvesting) vagy webkaparás (web scraping) egy olyan technika, amellyel automatizált módon ki tudjuk nyerni a weboldalakból a számunkra szükséges adatokat. Ezek éppúgy lehetnek hosszabb-rövidebb szövegek, mint táblázatos vagy strukturálatlan formában jelen lévő numerikus adatok. A cél tehát az, hogy egy olyan automatizmust hozzunk létre, amely a kérdéses adatokat kitermeli a megadott oldalakról és ezeket az igényeinknek megfelelő formába önti.
Ebben a blogposztban az 1896 és 2020 (2021) közötti nyári olimpiák nemzetek (nemzeti olimpiai bizottságok) szerinti bontásban elkészített éremtáblázatait aratom le a Wikipédiáról. Ezekre egy későbbi projekt miatt van szükségem.
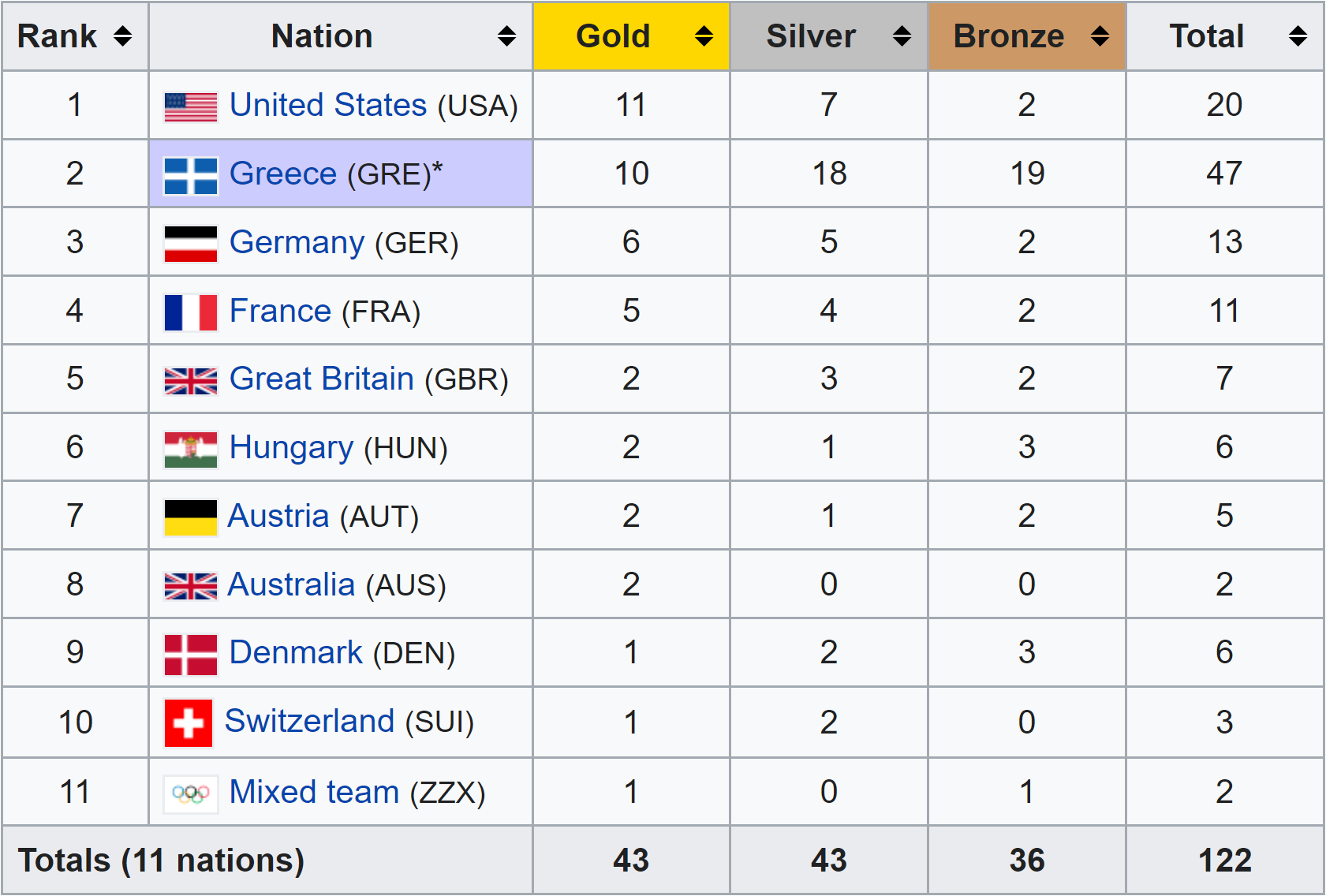
Az 1896-os nyári olimpia éremtáblázata nemzetek szerinti bontásban a Wikipédián
Elöljáróban fontos még megjegyezni, hogy nem minden weboldal tulajdonosa szereti vagy engedi ezt a tevékenységet. A webaratás elkezdése előtt erről mindig előzetesen tájékozódni kell! A Wikipédia, mint szabad enciklopédia esetében ilyen korlátozás nincsen. Az oldalak a CC-BY-SA-3.0 licenc alapján használhatók. Ez a forrás megnevezésének feltételével lehetővé teszi az átdolgozások, származékos művek létrehozását.
Az olimpiai adatok learatásának elvi alapjai
A webaratás akkor hatékony, ha ugyanazzal a kóddal egyszerre sok oldalról tudjuk begyűjteni az adatokat. Jelen esetben 29 olimpiáról és ugyanennyi weblapról van szó. Ez már akkora mennyiség, amelynél érdemes belekezdeni a programozásba. A kérdéses Wikipédia oldalakon viszont nemcsak az általunk megszerezni kívánt a táblázatok szerepelnek, hanem sok minden más is. Ebben az információhalmazban kell valahogy megragadni ezeket a táblákat.
Az 1896-os nyári olimpia éremtáblázatának oldala az angol nyelvű Wikipédián
Az egyik lehetséges módszer a Dokumentum Objektum Modell (Document Object Model / DOM) elemzése. A DOM lényege az, hogy a weblap hátterében álló HTML kód minden egyes eleme egy hierarchikus felépítésű rendszer részét képezi. Egy fa alakú struktúrát kell itt elképzelni. Ebben a rendszerben természetesen a táblázatunkat reprezentáló HTML kódrészletnek is pontosan meghatározható helye van. Jelen esetben a probléma az, hogy nem teljesen azonos felépítésű a 29 Wikipédia oldal, vagyis a DOM hierarchiájában nem mindig ugyanazon a szinten helyezkedik el ez a táblázat. Márpedig ha minden oldalra külön szabályt kell alkotni, vagy legalábbis vizsgálni kell annak a lehetőségét, akkor az alaposan lerontja a munka hatékonyságát. A DOM-tól függetlenül hivatkozhatnánk egyébként a HTML kód egyes konkrét elemeire is. De mivel a minket érdeklő oldalakon több táblázat, azaz a forráskódban több <table>...</table> elem található, ezért ezzel sem megyünk sokra.
Egy másik lehetőség annak kihasználása lenne, hogy a weboldalak kinézetét szabályozó CSS stílusleíró nyelv bizonyos esetekben megkívánja a HTML elemek egyedi vagy csoportos azonosítását. Ha például sok táblázat van egy oldalon, akkor az id=“azonosító” attribútum alkalmazásával egyedi neveket lehet rendelni azokhoz. Például így: <table id="azonosító">...</table>. A táblázatok egy csoportja pedig, az előbbihez hasonló módon megadva, a class=“azonosító” attribútum megléte esetén hivatkozható. Ezeket az úgynevezett szelektorokat tehát azért építik be a weblapokba, hogy egyedi kinézetet biztosíthassanak az oldal egyes elemeinek. Ugyanakkor a szelektorok nemcsak a CSS alkalmazásakor hasznosak, hanem a webaratáskor is megkönnyíthetik a szükséges tartalom kiválasztását. Mert az azonosítók segítségével hivatkozni tudunk arra. Alább a CSS szelektorokat fogom felhasználni az olimpiák helyszínére vonatkozó adatok kiválasztásakor. Az éremtáblázatok esetében viszont sajnos ez sem segít nekünk.
A helyzet tehát az, hogy az érintett Wikipédia oldalakon rendszerint több táblázat is van, amelyek nincsenek egyedileg azonosítva, és a DOM-ban elfoglalt helyük is változó. De semmi gond! Egy kis agyalás után erre is van megoldás.
Ebben a helyzetben azt fogom csinálni, hogy egy character típusú vektorba letöltöm az aktuálisan vizsgált oldal HTML kódját. Vagyis a vektor minden eleme a HTML dokumentum egy-egy sorát reprezentálja majd. Az oldal kódjában biztos pontnak számít a “Rank” szó, mivel ez minden számunkra fontos táblázat fejlécében előfordul, az irreleváns táblázatokban viszont nem található meg. (Az angol nyelvű Wikipédiával dolgoztam.) Megkeresem tehát a HTML oldal azon sorát, amely ezt a szót tartalmazza. Mivel egy táblázatról beszélünk, így bizonyosak lehetünk abban, hogy valahol előtte kell lennie egy <table> és utána egy </table> HTML elemnek. Ezért lekérem azokat a sorokat is, amelyekben ezek előfordulnak. Itt nyilván számolnunk kell azzal az eshetőséggel, hogy az adott oldalon több táblázat szerepel és ennek megfelelően több találatot kapunk. A lehetséges sorok közül a <table> elem esetében azt kell kiválasztanunk, amely a közvetlenül megelőzi vagy megegyezik a “Rank”-ot tartalmazó sorral, a </table> elemnél pedig azt, amely közvetlenül követi vagy megegyezik az említett viszonyítási pont sorával. Ezután már minden további nélkül ki tudjuk szűrni a HTML dokumentumból a releváns sorokat, majd azokból a releváns részeket.
A feladat gyakorlati megvalósítása
Az alábbiakban R nyelven (v4.0.3) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
Az olimpiai éremtáblázatok learatása során a szövegbányászati feladatokhoz a stringr, a webaratáshoz pedig az rvest csomagot használom. Az alább közölt kódot megjegyzésekkel láttam el az abban való könnyebb eligazodás érdekében.
# A szükséges csomagok betöltése.
# A legelső használat előtt az install.packages("...") utasítással telepíteni
# kell ezeket. A ... helyére az adott csomag neve írandó.
library(stringr)
library(rvest)
# Ebben az adatkeretben fogjuk gyűjteni a learatott adatokat.
tablaGyujto <- data.frame(orszag = as.character(),
arany = as.numeric(),
ezust = as.numeric(),
bronz = as.numeric(),
osszesen = as.numeric(),
ev = as.numeric(),
helyszin = as.character())
# A nyári olimpiák éveinek legenerálása.
ev <- setdiff(seq(1896, 2020, 4), c(1916, 1940, 1944))
# Az alábbiakban sorban végig megyünk az olimpiák évein és
# a megfelelő Wikipédia oldalról kinyerjük a szükséges adatokat.
for (i in ev) {
# Az adott évhez tartozó Wikipédia oldal URL-jének legenerálása.
url <- str_glue("https://en.wikipedia.org/wiki/{i}_Summer_Olympics_medal_table")
# Az oldal HTML kódjának beolvasása.
tabla <- readLines(url)
# A "Rank" szót tartalmazó sor helyének megállapítása az oldalon belül.
biztosPont <- str_which(tabla, "Rank")
# A "Rank"-hoz legközelebbi <table> elem helyének megállapítása.
tablaStart <- str_which(tabla, "<table")
tablaStart <- tail(tablaStart[tablaStart <= biztosPont], 1)
# A "Rank"-hoz legközelebbi </table> elem helyének megállapítása.
tablaStop <- str_which(tabla, "</table>")
tablaStop <- head(tablaStop[tablaStop >= biztosPont], 1)
# Az oldal HTML kódjának leszűkítése a táblázat helyére és
# a sorok összevonása egyetlen karakterláncba.
tabla <- tabla[tablaStart:tablaStop] %>%
paste(collapse = "")
# A karakterlánc elejének és végének megtisztítása a felesleges elemektől.
tabla <- str_sub(tabla, str_locate(tabla, "<table")[1], str_locate(tabla, "</table>")[2])
# Egy virtuális HTML dokumentum létrehozása a karakterláncból,
# majd ennek adatkeretté alakítása.
tabla <- minimal_html(tabla) %>%
html_table() %>%
as.data.frame()
# Az olimpia évének hozzáadása az adatkerethez.
tabla$ev <- i
# Az olimpia helyszínének begyűjtése, megtisztítása és hozzáadása
# az adatkerethez.
tabla$helyszin <- read_html(url) %>%
html_nodes(css = ".location") %>%
html_text() %>%
str_remove_all("\n") %>%
str_replace("/", "/ ") %>%
str_squish()
# A "Rank" nevű oszlop eltávolítása. Erre nincs szükségünk, mert egyébként
# bárhogy átrendezhetjük a táblázatot a jövőben.
tabla$Rank <- NULL
# Az adatkeret utolsó, összegző sorának eltávolítása.
tabla <- tabla[-nrow(tabla),]
# Az adatkeret oszlopainak átnevezése.
colnames(tabla) <- colnames(tablaGyujto)
# Az adatkeret tartalmának hozzáadása az eddig begyűjtött adatokhoz.
tablaGyujto <- rbind(tablaGyujto, tabla)
}
Az adatok összegyűjtése után a táblázatunk 7 mezőt és 1344 rekordot tartalmaz. Nézzük meg ennek az első olimpiára vonatkozó sorait! Ha jól dolgoztunk, akkor az adataink megegyeznek a fentebb képként beillesztett táblázat tartalmával.
tibble::as.tibble(tablaGyujto[tablaGyujto$ev == 1896,]) %>% print(n = Inf)## # A tibble: 11 × 7
## orszag arany ezust bronz osszesen ev helyszin
## <chr> <int> <int> <int> <int> <dbl> <chr>
## 1 United States 11 7 2 20 1896 Athens, Greece
## 2 Greece* 10 18 19 47 1896 Athens, Greece
## 3 Germany 6 5 2 13 1896 Athens, Greece
## 4 France 5 4 2 11 1896 Athens, Greece
## 5 Great Britain 2 3 2 7 1896 Athens, Greece
## 6 Hungary 2 1 3 6 1896 Athens, Greece
## 7 Austria 2 1 2 5 1896 Athens, Greece
## 8 Australia 2 0 0 2 1896 Athens, Greece
## 9 Denmark 1 2 3 6 1896 Athens, Greece
## 10 Switzerland 1 2 0 3 1896 Athens, Greece
## 11 Mixed team 1 0 1 2 1896 Athens, Greece
Végezetül távolítsuk el az országok (nemzeti olimpiai bizottságok) neve mellett látható rövidítéseket és egyéb felesleges karaktereket egy reguláris kifejezéssel.
tablaGyujto$orszag <- str_remove(tablaGyujto$orszag, "\\s\\(.+")
Alább álljanak itt a táblázatból a Magyarországra vonatkozó adatok.
tibble::as.tibble(tablaGyujto[tablaGyujto$orszag == "Hungary",]) %>% print(n = Inf)## # A tibble: 27 × 7
## orszag arany ezust bronz osszesen ev helyszin
## <chr> <int> <int> <int> <int> <dbl> <chr>
## 1 Hungary 2 1 3 6 1896 Athens, Greece
## 2 Hungary 1 2 2 5 1900 Paris, France
## 3 Hungary 2 1 1 4 1904 St. Louis, United States
## 4 Hungary 3 4 2 9 1908 London, Great Britain
## 5 Hungary 3 2 3 8 1912 Stockholm, Sweden
## 6 Hungary 2 3 4 9 1924 Paris, France
## 7 Hungary 4 5 0 9 1928 Amsterdam, Netherlands
## 8 Hungary 6 4 5 15 1932 Los Angeles, United States
## 9 Hungary 10 1 5 16 1936 Berlin, Germany
## 10 Hungary 10 5 12 27 1948 London, Great Britain
## 11 Hungary 16 10 16 42 1952 Helsinki, Finland
## 12 Hungary 9 10 7 26 1956 .mw-parser-output .plainlist ol,.mw…
## 13 Hungary 6 8 7 21 1960 Rome, Italy
## 14 Hungary 10 7 5 22 1964 Tokyo, Japan
## 15 Hungary 10 10 12 32 1968 Mexico City, Mexico
## 16 Hungary 6 13 16 35 1972 Munich, West Germany
## 17 Hungary 4 5 13 22 1976 Montreal, Canada
## 18 Hungary 7 10 15 32 1980 Moscow, Soviet Union
## 19 Hungary 11 6 6 23 1988 Seoul, South Korea
## 20 Hungary 11 12 7 30 1992 Barcelona, Spain
## 21 Hungary 7 4 10 21 1996 Atlanta, United States
## 22 Hungary 8 6 3 17 2000 Sydney, Australia
## 23 Hungary 8 6 3 17 2004 Athens, Greece
## 24 Hungary 3 5 2 10 2008 Beijing, China
## 25 Hungary 8 4 6 18 2012 London, Great Britain
## 26 Hungary 8 3 4 15 2016 Rio de Janeiro, Brazil
## 27 Hungary 6 7 7 20 2020 Tokyo, Japan
A Wikipédiáról learatott olimpiai adatokkal további terveim vannak. Hogy mit akarok ezekkel tenni, az majd kiderül a következő posztból. 🙂