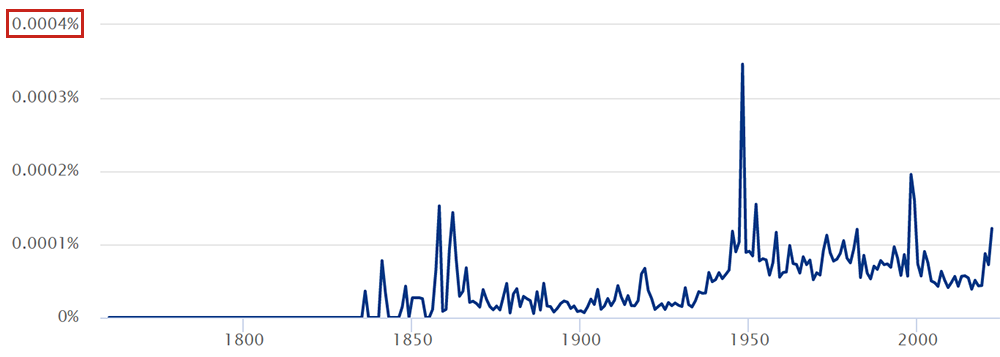
Az Arcanum Digitális Tudománytár analitika diagramja tehát arról ad tájékoztatást, hogy a keresőkifejezésünk alapján megtalált szavak száma hogyan aránylik az adatbázisban rögzített összes szóhoz. Itt általában nagyon kicsi, a százalék tört részét kitevő értékeket kapunk eredményül. Ezeket a rendszer az 1760 utáni évek mindegyikére kiszámítja és egy vonaldiagramon ábrázolja. Az analitika diagram lehetővé teszi, hogy felfigyeljünk bizonyos tendenciákra vagy egyedi jelenségekre.
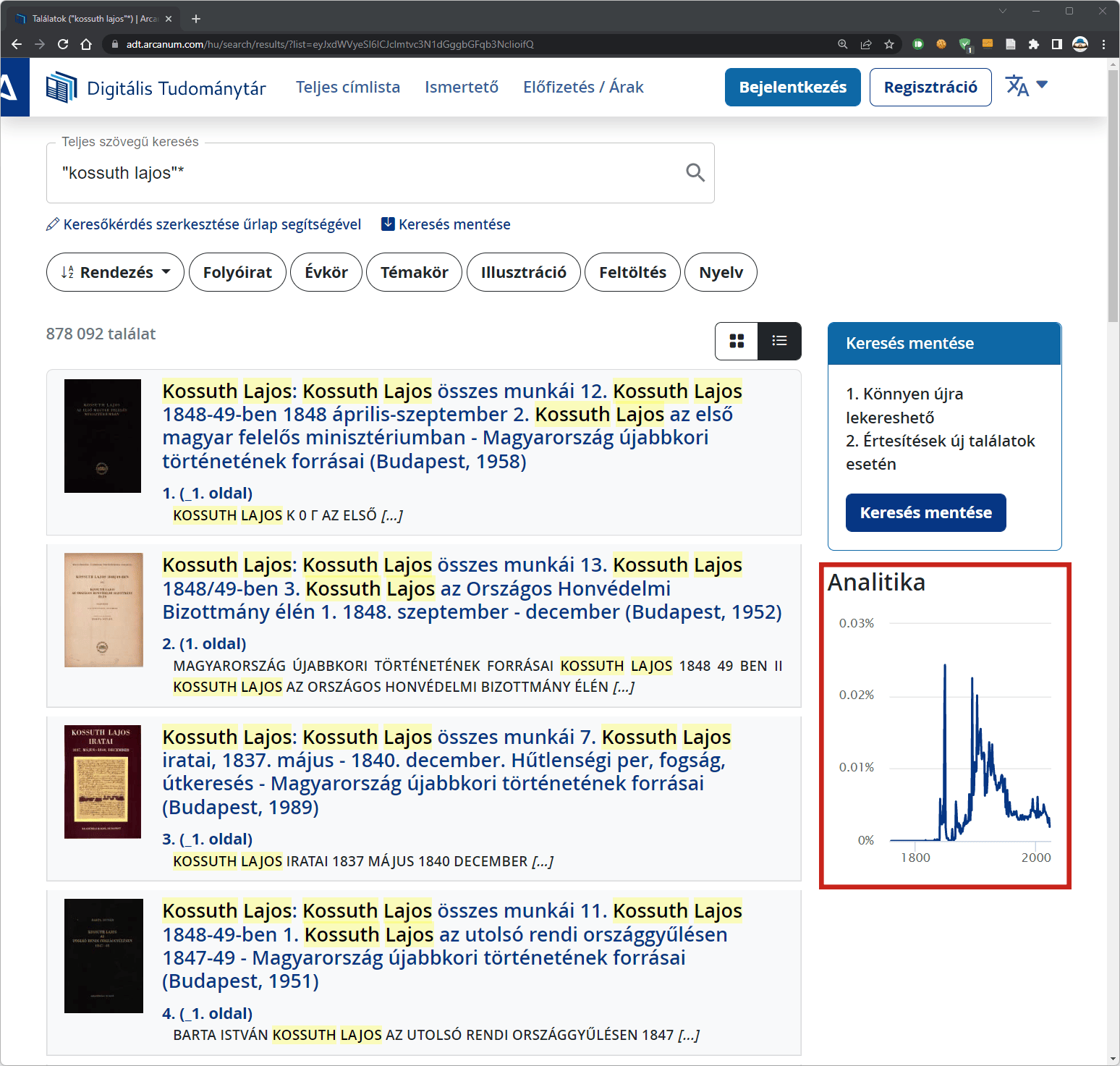
Az ADT-n lévő analitika diagram alapértelmezetten a találati lista jobb felső részén foglal helyet, viszonylag kis méretben. Az oldal nagyításával vagy a böngészőablak átméretezésével le lehet ugyan ügyeskedni a találati lista alá, ahol már elfogadható részletességgel jelenik meg. Lementeni azonban csak a képmetsző alkalmazással tudjuk, raszteres formátumban. Amit sajnos sem tartalmilag, sem vizuálisan nem tudunk a saját igényeinkhez igazítani.
Azt szeretném tehát elérni, hogy szerkeszthető formában is rendelkezésre álljon e diagram. Ez lehetővé tenné nemcsak a vizuális újragondolását, hanem azt is, hogy alkalmasint több keresőkifejezéshez tartozó vonaldiagramot egyetlen ábrán egyesíthessünk. Úgy, ahogy az alábbi példán látható.
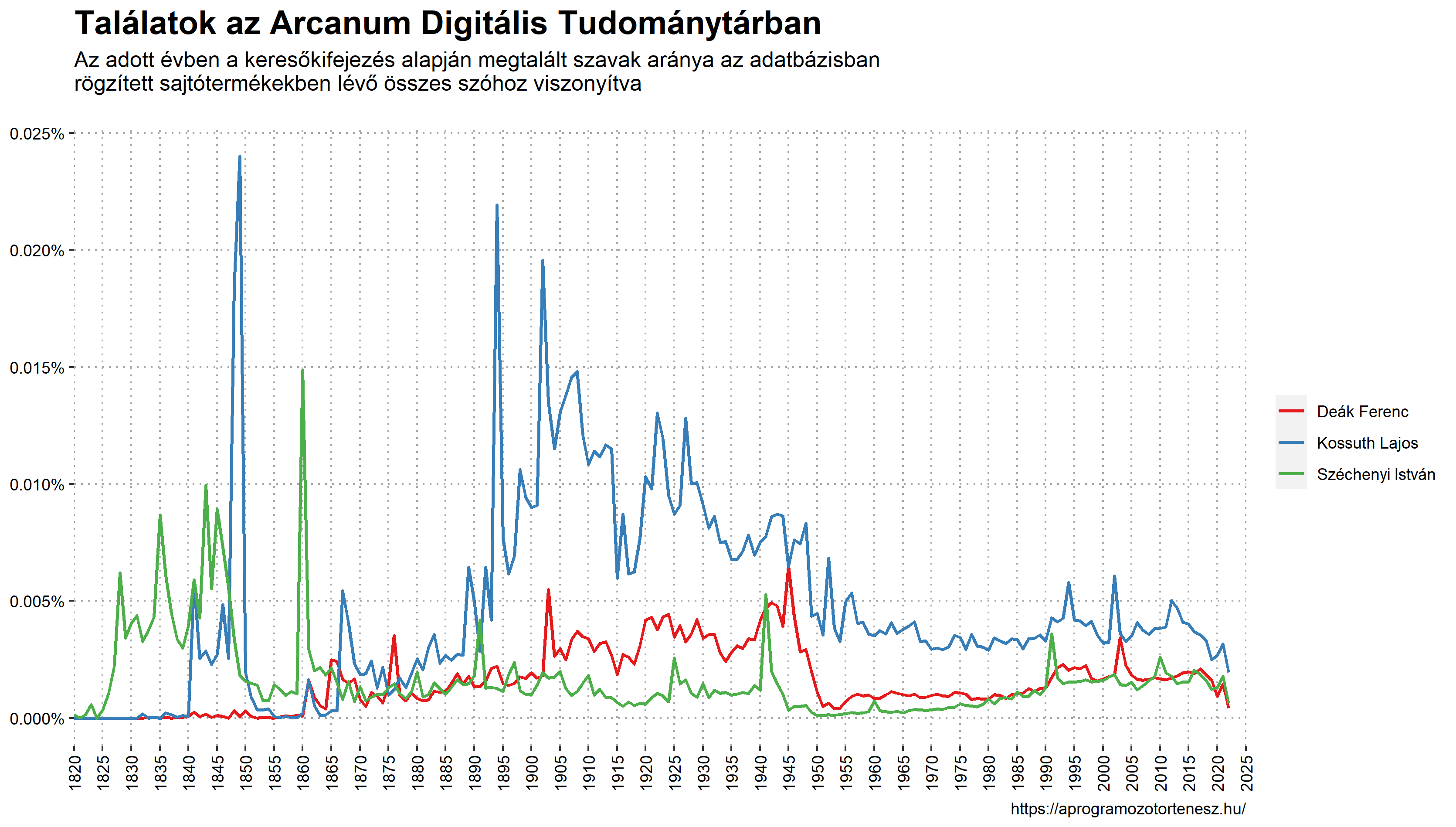
Akkor vágjunk is bele! 😉
Az eredeti diagram hátterében álló titokzatos adatok
Mindenekelőtt természetesen szükségünk van azokra az adatokra, amelyekből az ADT-n felrajzolásra kerül az analitika diagram. Ezekhez úgy juthatunk hozzá, ha a Chrome böngészőben a kék vonaldiagram fölé visszük az egérmutatót, majd jobb gombbal kattintunk és a Vizsgálat menüpontot választjuk. (Lehet, hogy más böngészőben is működik, de itt biztosan.)
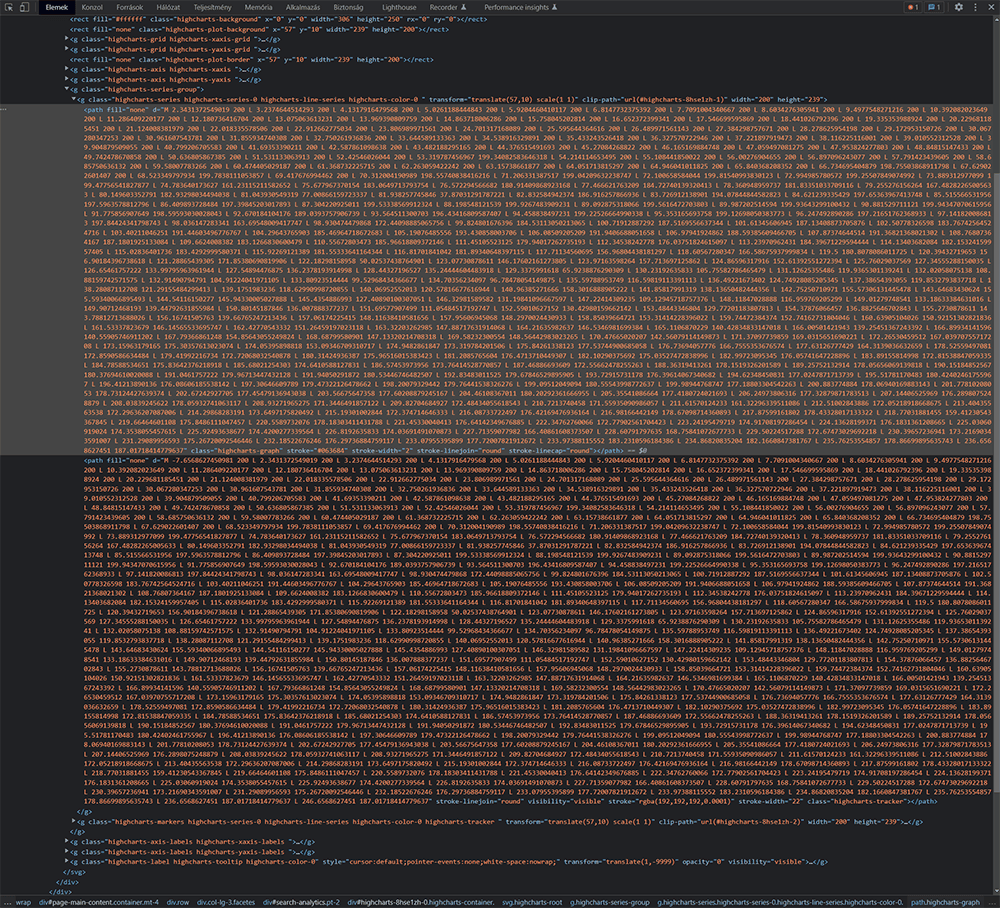
A böngészőben megnyíló új panelen az oldal forráskódjának egy olyan részéhez kell jutnunk, ahol a fenti ábrának megfelelően egy nagy halom szám látható, közöttük L betűkkel. Ha véletlenül nem ezt az eredményt kapnánk, ami néha előfordul, akkor addig ismételgessük a műveletet, amíg végül ide jutunk.
A két, szemre nagyon hasonló kódblokk közül nekünk a felsőre lesz szükségünk. Alább egy kivágott részletet mutatok ebből.
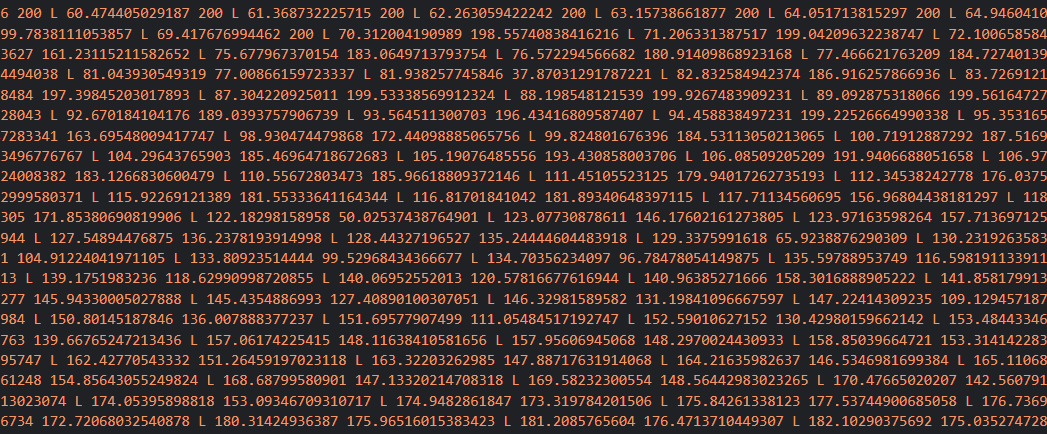
De mit látunk itt? Első ránézésre ez nyilvánvalóan nem egyértelmű. Az olvasók megnyugtatására írom: sokadikra sem. 😀 Eleinte én is csak annyit sejtettem, hogy ezek a számok az egyes adatpontok koordinátái lesznek.
Az ilyen esetekben az a legjobb stratégia, ha elkezdünk kísérletezgetni az adatokkal. Amennyiben bal gombbal duplán kattintva kijelöljük, majd átírjuk valamelyik számot, akkor az Enter megnyomását követően megváltozik az oldalon lévő diagram kinézete is. (Mivel a gépünkre letöltődött forráskóddal dolgozunk, ezért magától értetődően csak addig áll fenn ez a változás, ameddig újra nem töltjük a weboldalt.) A számok átírogatásával játszadozva és a kapott eredményen elgondolkodva egy idő után meg lehet fejteni, hogy milyen szisztéma alapján vannak megadva ezek az adatok.
Ez a következő. Számpárokat látunk, L betűkkel elválasztva. Például: “… L 150.80145187846 136.007888377237 L …” Egy-egy számpár egy konkrét évnek felel meg. Az első 1760-nak, sorrendben az utolsó pedig (jelen pillanatban) 2022-nek.
-
A számpárok első eleme az adatpont “x” koordinátája. Hogy miért pont ezek a számok vannak itt, az egyáltalán nem érdekes nekünk. A lényeg a sorrenden van, amiből ki lehet következtetni az éveket.
-
A számpárok második eleme az adatpont “y” koordinátája, 0 és 200 közötti tartományban mozgó értékekkel. Ennél azonban van egy csavar a dologban. Ugyanis – ki tudja miért – a 200-as szám felel meg a 0-nak, vagyis amikor 0 találat van a kérdéses évben, akkor itt 200 szerepel. És minél nagyobb a találatok aránya, annál jobban közelít ez a szám a 0-hoz. (Mellékesen megjegyzem, hogy egy MacBook-on is kipróbálva nem 200, hanem 204 volt a legmagasabb szám. De ez a lényegen nem változtat.)
Miután sikerült megfejteni a diagram hátterében álló titokzatos adatok rejtélyét, bele is foghatunk abba, hogy R nyelven átkonvertáljuk ezeket egy olyan formátumba, ami alkalmas a saját vizualizációnk elkészítésére.
A bemeneti adatok előkészítése
A fentiekben körvonalazott célnak megfelelően egy olyan diagramot akarunk létrehozni, amelyen egyszerre több keresőkifejezés időbeli gyakoriságát is ábrázolni lehet.
Az ehhez vezető úton az első lépés az adatok beszerzése. Az ADT-n rákeresünk a minket érdeklő kifejezésre, majd a korábban látott módon elővarázsoljuk a releváns kódszakaszt. Ezt kijelöljük, másoljuk és beillesztjük egy új szöveges dokumentumba. Minden keresőkifejezésnek külön szöveges fájlt kell létrehoznunk.
A fájlokat ne tetszés szerint, hanem a lentebb ismertetett szabály alapján nevezzük el! Azért fontos ez, mert a fájlnevekben olyan plusz adatokat is elhelyezünk, amelyekre szükségünk van a diagram előállításához, de magából a fájl tartalmából nem derülnek ki.
Ez egyrészt az adatsor megnevezése, amit a diagramunk jelmagyarázatában szerepeltetni akarunk. Másrészt pedig az eredeti analitika diagram y tengelyén legfelül látható százalékos érték. Ez ahhoz kell, hogy közös alapra tudjuk hozni a függőlegesen eltérő ábrázolási tartományban mozgó keresőkifejezéseket.
A fájlok elnevezésére vonatkozó szabály tehát a következő: “megnevezés_százalék.txt”, például: “jobbágyfelszabadítás_0.0004.txt”. A megnevezés esetében a diagram jelmagyarázatban pontosan azt fogjuk látni, amit ide beírtunk. Ez lehet akár több szó is, megkülönböztetve a kis- és nagybetűket. A százalékos értéknél pedig figyeljünk arra, hogy az R-ben nem vessző, hanem pont szerepel a tizedes törtekben. Magát a százalék jelet ne írjuk bele a fájlnévbe! Ha a fájlok elnevezése során következetlenül járunk el, akkor egy hibaüzenet kíséretében leáll a kód futása.
A szöveges fájloknak hozzunk létre egy külön mappát. Az elkészült diagramon annyi adatsor lesz, ahány szöveges fájl van a munkakönyvtárunkban. Ezt automatikusan felismeri a rendszer. Azaz a diagram konkrét tartalmát a fájlok cserélgetésével lehet befolyásolni.
A bemeneti adatok átalakítása
Az alábbiakban R nyelven (v4.2.2) írt kódot használok a feladat végrehajtásához. A magyarázó szövegek közé ékelt fekete kódblokkok tartalmát az RStudio-ban egymás alá illesztve elvileg bárki által reprodukálható az itt bemutatott műveletsor. A kódblokkok # kezdetű sorai pusztán magyarázó funkcióval bírnak, ezekre a program futtatásakor nincs szükség.
A feladat végrehajtásához öt csomagot fogok használni. A szöveges fájlok a readtext csomaggal kerülnek beolvasásra. Ezek tartalmát a stringr és a rebus csomagokkal manipulálom. A dátumok kezelése a lubridate, a diagram megrajzolására a ggplot2 csomaggal történik. Egy adott függvény származási helyének egyértelmű beazonosításához a csomag::függvény() formulát használom a kódban. (A base csomag függvényei automatikusan betöltődnek, ezt nem jelölöm külön.)
Töltsük be ezeket a csomagokat és adjuk meg a munkakönyvtárunk elérési útvonalát!
|
|
Először readtext::readtext() függvénnyel beolvassuk a szöveges fájlokat az adatok elnevezésű adatkeretbe, majd a stringr::str_remove() függvényt használva eltávolítjuk a szövegek elején és végén található felesleges HTML kódokat. Ehhez reguláris kifejezéseket használunk, amelyeket a rebus csomag által megkívánt módon adunk meg.
|
|
Ekkor egy adatkeretet kaptunk tehát, amelynek minden sora egy-egy szöveges fájlnak felel meg.
## readtext object consisting of 3 documents and 2 docvars.
## # A data frame: 3 × 4
## doc_id text docvar1 docvar2
## <chr> <chr> <chr> <dbl>
## 1 Deák Ferenc_0.0075.txt "\"2.20588235\"..." Deák Ferenc 0.0075
## 2 Kossuth Lajos_0.03.txt "\"2.34313725\"..." Kossuth Lajos 0.03
## 3 Széchenyi István_0.02.txt "\"2.27450980\"..." Széchenyi István 0.02
Ahány szöveges fájl van a munkakönyvtárunkban, annyi sora lesz ennek a táblázatnak. A text oszlop tartalmazza magát a szöveget. (Helyhiány miatt ennek természetesen csak töredékét láthatjuk fentebb.) A docvar1 oszlopban az adatsor megnevezése, a docvar2 oszlopban pedig az analitika diagram y tengelyen lévő legnagyobb százalékos érték szerepel. Utóbbi kettőt adtuk meg a fájlok elnevezésében, amely egyébként bekerült a táblázat doc_id oszlopbába.
A továbbiakban a for ciklus segítségével végig megyünk ennek a táblázatnak minden egyes során és feldolgozzuk azokat. Azaz annyi alkalommal fog lefutni a kódunk, ahány sora van aktuálisan a táblázatunknak.
Az 1. sor text oszlopának tartalma jelenleg a következő (ez egy kiragadott részlet belőle):
## [1] " L 40.09317467445 200 L 40.935114503817 200 L 41.777054333184 200 L 42.61899416255 200 L 43.460933991917 200 L 44.302873821284 200 L 45.144813650651 200 L 45.986753480018 200 L 46.828693309385 200 L 47.670633138752 200 L 48.512572968118 200 L 49.354512797485 200 L 50.196452626852 200 L 51.038392456219 200 L 51.880332285586 200 L 52.722272114953 200 L 53.56421194432 200 L 54.406151773687 200 L 55.248091603053 200 L 56.09003143242 200 L 56.931971261787 200 L 57.773911091154 200 L 58.615850920521 200 L 59.457790749888 200 L 60.299730579255 200 L 61.141670408621 200 L 61.983610237988 200 L 62.825550067355 200 L 63.667489896722 199.13948598701333 L 64.509429726089 199.13524442154284 L 65.351369555456 200 L 66.193309384823 199.0382722561081 L 67.035249214189 200 L 67.877189043556 199.26163975320495 L 68.719128872923 199.25507849074992 L 69.56106870229 197.91026167311503 L 70.403008531657 192.89731031129645 L 71.244948361024 198.63610507753359 L 72.086888190391 195.69343765295486 L "
A célunk az, hogy ezt a karakterláncot átkonvertáljuk egy olyan adatkeretté, amelynek minden sora egy-egy adatpontnak felel meg, és az oszlopai az adatpontok x és y koordinátáját, valamint az adatsor megnevezését tartalmazzák.
A később közölt kódban először a stringr::str_split() függvénnyel felszeleteljük ezt a karakterláncot az L betűk mentén, az eredményül kapott kisebb karakterláncok elejéről és végéről pedig az stringr::str_trim() függvénnyel eltávolítjuk a felesleges szóközöket. Ennek eredményeként olyan karakterláncokat kapunk, az 1760 óta eltelt évek számának megfelelő mennyiségben, amelyek szóközzel elválasztva tartalmazzák az adatpontok két koordinátáját, például: “40.09317467445 200”. Ezt a szóköz mentén ugyancsak az str_split() függvénnyel tovább daraboljuk két különálló értékké. Végül egy adatkeretté alakítjuk mindezeket és elmentjük az adatsor nevű változóba. Az oszlopok itt az ev és a gyakorisag nevet kapják. Lássuk ennek 15 darab, véletlenszerűen kiválasztott sorát!
## ev gyakorisag
## 52 45.144813650651 200
## 248 210.16502020656 157.0639229612682
## 13 12.309160305343 200
## 81 69.56106870229 197.91026167311503
## 176 149.54535249214 125.27480567692785
## 8 8.0994611585091 200
## 212 179.85518634935 172.84433784296886
## 124 105.76448136507 169.43469422087955
## 78 67.035249214189 200
## 85 72.928828019757 199.22670386801033
## 242 205.11338123035 152.99341185123592
## 75 64.509429726089 199.13524442154284
## 83 71.244948361024 198.63610507753359
## 22 19.886618769645 200
## 246 208.48114054782 151.01472845396034
Az adatpontok koordinátái jól szétválasztódtak tehát, de tartalmilag még nem azok, amelyekre nekünk szükségünk van.
Az ev nevű oszlopban – nomen est omen – az éveknek kellene szerepelniük 1760-tól napjainkig. Ehhez képest furcsa számokat látunk itt. Mivel azonban tudjuk, hogy az egyes adatpontok időrendben követik egymást, így minden további nélkül le tudjuk cserélni ezeket egy 1760 és (jelenleg) 2022 közötti számokat tartalmazó vektorral. A kódban a lubridate::year(lubridate::today()) paranccsal állítottam elő az utolsó számot, a most aktuális évet, így az algoritmus remélhetőleg jövőre és a későbbiekben is működőképes marad.
Más szempontból, de ugyancsak problémás a gyakorisag nevű oszlop tartalma. Ide a százalékos értékek jönnének, jelen pillanatban viszont 0 és 200 közötti számok szerepelnek itt. Ráadásul úgy, hogy a 200 felel meg a legkisebb, a 0 pedig a legnagyobb gyakoriságnak. Bővebben lásd a fentebbi magyarázatot!
Először is meg kell fordítanunk a skála irányát. Ezt úgy tudjuk elérni, hogy a gyakorisag oszlopban szereplő számokból kivonunk 200-at, majd ennek az abszolút értékét vesszük. Ezzel elértük, hogy a skálánkon a 0 jelentse a legkisebb, a 200 pedig a legnagyobb gyakoriságot. (A kódban a 200-at a maximum nevű változó tartalmazza.)
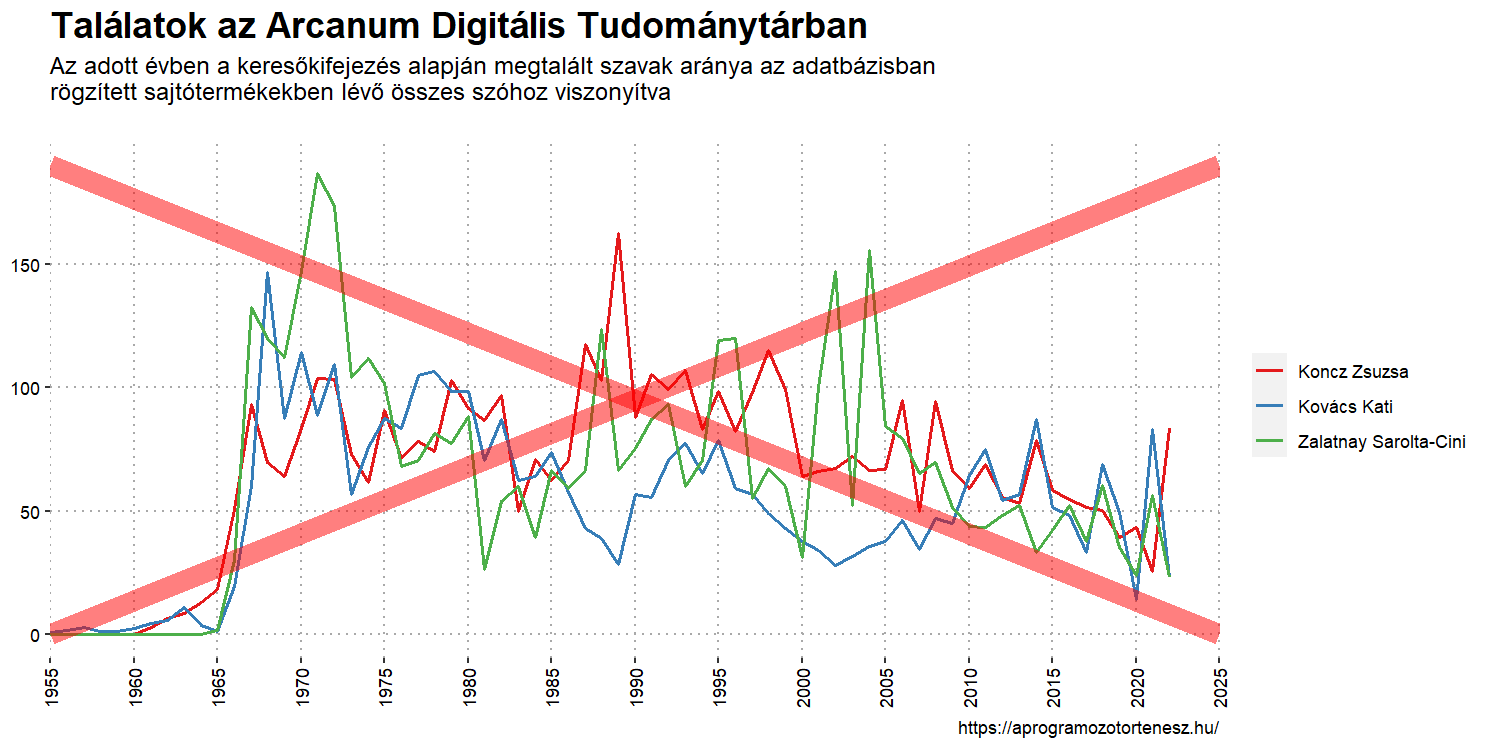
De ezzel még értünk a probléma végére! A gond az, hogy bármilyen keresőkifejezést is használunk az ADT-ben, az analitika diagram hátterében álló számok mindig 0 és 200 között mozognak. A maximális érték akkor is 200, ha egy keresőkifejezésnél nagyon sok találat van, és akkor is, ha egy másiknál nagyságrendekkel kevesebb. Egy önállóan ábrázolt adatsornál ez nem jelent problémát, mi azonban több adatsort akarunk egymás mellé helyezni. Az egymáshoz viszonyított arányokat figyelmen kívül hagyva egy eltorzult ábrát kapnánk.
Nézzünk erre egy példát! Rákeresve Koncz Zsuzsa, Kovács Kati és Zalatnay Sarolta/Cini nevére, az alábbi analitika diagramokat láthatjuk.
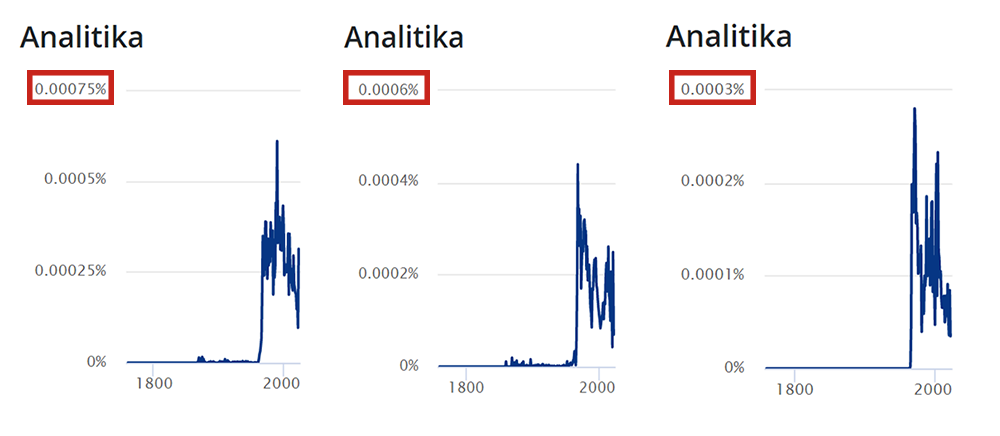
Amennyiben ezeket csak úgy egymásra helyeznénk, akkor a következő ábrához jutnánk.
Ha viszont az arányokat is figyelembe vesszük, abban az esetben egészen mást látunk!
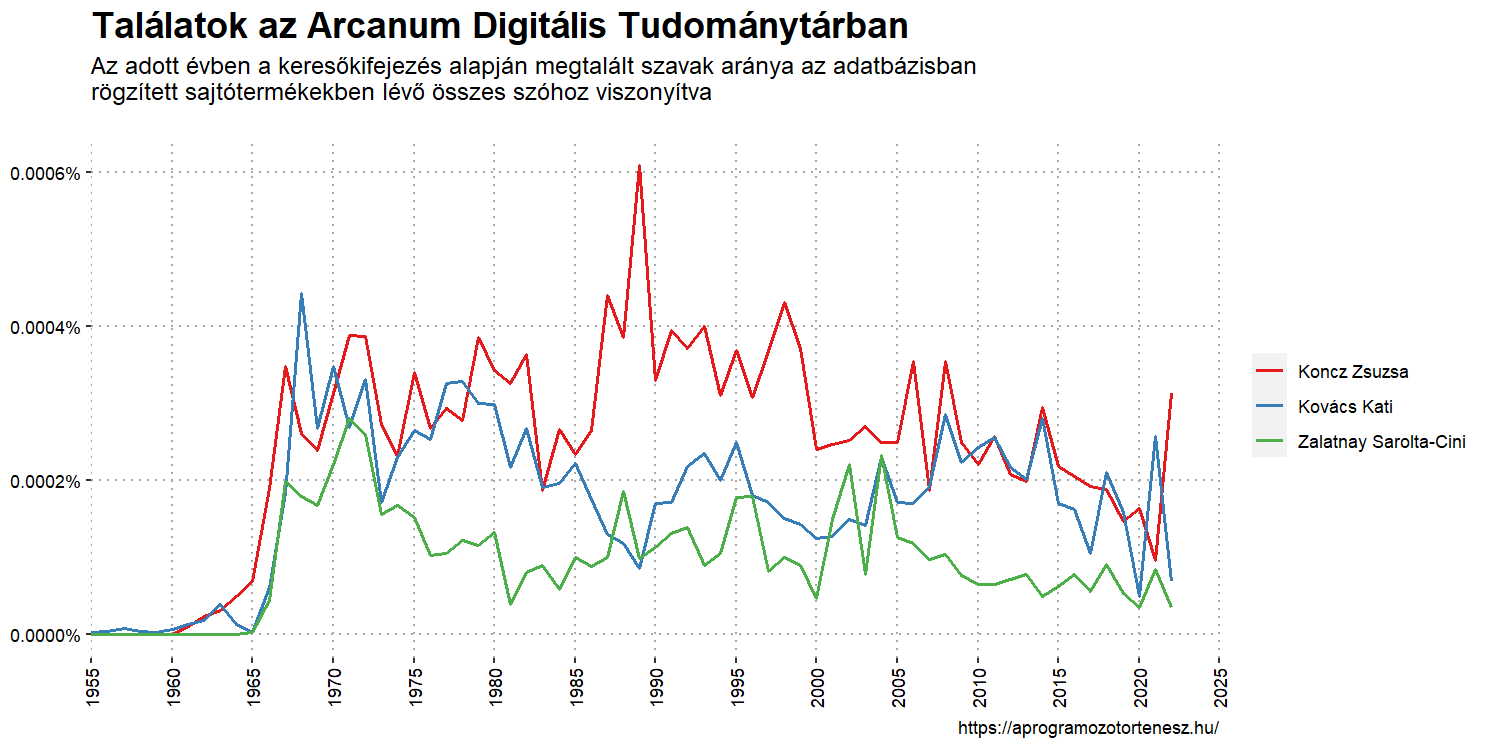
A diagramok aránytartását úgy tudjuk elérni, ha a fájlok elnevezéséből begyűjtött százalékos értékeket elosztjuk 200-zal, majd beszorozzuk ezzel a táblázat gyakorisag nevű oszlopában lévő számokat. Az eredményt normálalakban fogjuk megkapni, de ettől ne ijedjünk meg.
Végül a feldolgozott adatsort tartalmazó táblázathoz egy új oszlopban hozzáadjuk magának az adatsornak a megnevezését, majd az rbind() függvénnyel elmentjük az adatGyujto táblázatban.
Ezt követően a for ciklus átugrik az adatok nevű táblázat következő sorára és kezdődik elölről a folyamat, egészen addig, amíg van feldolgozatlan sora ennek az adatkeretnek.
Lássuk tehát most már a fentiekhez tartozó kódblokkot!
|
|
Az újragondolt analitika diagram elkészítése
Mindezek után nincs más dolgunk, mint a ggplot2 csomaggal felrajzoltatni a diagramunkat. Ehhez a fentiekben előállított adatGyujto nevű táblázatból érkeznek a bemeneti adatok.
Mivel a konkrét keresőkifejezésekhez tartozó adatsorok nem feltétlenül fedik le az 1760-tól napjainkig tartó időszak egészét, ezért a start, a stop és az osztaskoz elnevezésű változók tartalmának átírásával szabályozni tudjuk a ténylegesen ábrázolt időintervallumot. Itt arra kell figyelni, hogy a kezdő és a befejező évek közötti különbség maradéktalanul osztható legyen az osztásközként megadott számmal.
|
|
Végezetül nézzünk meg egy újabb példát, amely Ferenc József, Horthy Miklós, Szálasi Ferenc, Rákosi Mátyás és Kádár János nevének gyakoriságát mutatja meg az ADT adatbázisa alapján. Vagyis ezúttal 5 adatsorral próbálkozunk.
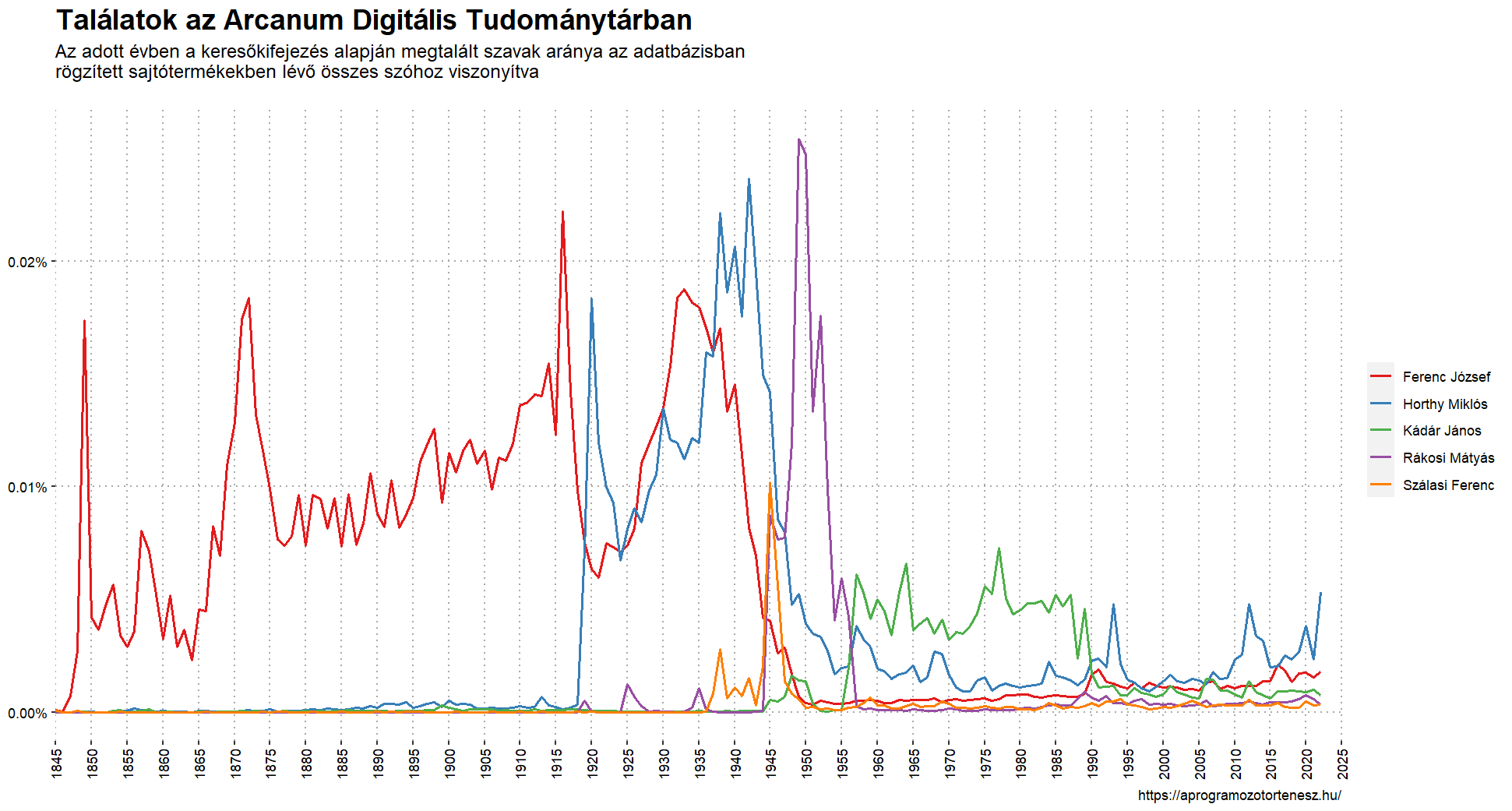
Ezzel készen is vagyunk. 😃 A diagram vizuális megjelenítését természetesen még tovább lehetne gondolni, jobban személyre lehetne szabni, hiszen a ggplot2 csomag a legapróbb részletekig lehetővé teszi ezt. A célom azonban az volt, hogy automatizáltan működjön az algoritmus. Így azok is használni tudják, akik nem kívánnak elmélyedni a ggplot2 csomag működésének finomságaiban.
Magától értetődő továbbá, hogy a diagramunk tartalmának minősége az ADT-n használt keresőkifejezésünk minőségétől függ. Hiszen onnan érkeznek a bemeneti adatok. Minél jobban specifikáljuk a keresőkifejezést, annál minőségibb találatokat kapunk. Amelyekben benne van minden, amit látni akarunk, de nincsenek benne tömegesen megtévesztő vagy irreleváns találatok. Meg kell tanulni tehát ADT-n való keresést!